
I. Introduction to Informatica Cloud Transformations
Transformations are mapping objects which represents the operation that needs to be performed on the data in the Informatica Cloud Data Integration mappings. There are several transformations that are offered by Informatica Cloud with each having its own properties and operation that it performs.
The transformations in Informatica Cloud are classified based on their connectivity and how they handle the rows passing through them.
Based on connectivity, the transformations are classified as
- Connected Transformation
- Unconnected Transformation
Connected Transformation
A Connected transformation is an inline transformation which stays in the flow of the mapping and connected to other transformations in the mapping.
Unconnected Transformation
An Unconnected transformation is not connected to any other transformation in the mapping. They are usually called within another transformation and returns a value to that transformation.
Based on how the transformation handles the rows passing through it, the transformations are classified as
- Active Transformation
- Passive Transformation
Active Transformation
An Active transformation can change the number of rows passing through it. Also a transformation is considered active when it can change the transaction boundary or position of the rows passing through it.
Any transformation that splits or combines the data streams or reduce, expand or sort the data is an active transformation because it cannot be guaranteed that when the data passes through it, the number of rows and their position in the data stream are always unchanged.
Passive Transformation
A Passive transformation does not change the number of rows passing through it, maintains the transaction boundary and position of the rows passing through it.
Let us discuss about the various transformation available in Informatica Cloud.
1. Source Transformation in Informatica Cloud
Source transformation is an active and connected transformation in Informatica Cloud. It is used to read and extract the data from the objects connected as source. The Source transformation can read data from a single source object or multiple source objects based on the connection type.
When you configure a Source transformation, you define Source properties on the following tabs of the Properties panel:
- Source tab: Select the Connection, Source Type and Source Object. You can also configure the advanced properties depending upon the source connection.
- Fields tab: Configure the fields of the object selected as source.
- Partitions tab: Configure the partitioning type based on the source connection.
1.1 Database objects as Source Object
When the connection type is any database connection, you could select the source type as
- Single Object: A single database object can be selected as a source.
- Multiple Objects: Multiple database objects with existing relationship at database level could be selected as sources.
- Query: A SQL query on the database objects can be used to fetch data from the database.
- Parameter: The entire source object could be parameterized in the mapping for which the value could be passed from a mapping task. In the mapping task you could again select a single or multiple source objects as source or even select Query option to pass SQL query as source.
Under Query Options tab of Source transformation
- You can configure conditions to Filter data read from database object.
- You can configure fields to Sort the data read from database object.
- You can select only distinct rows to be read from database object by checking Select Distinct option.
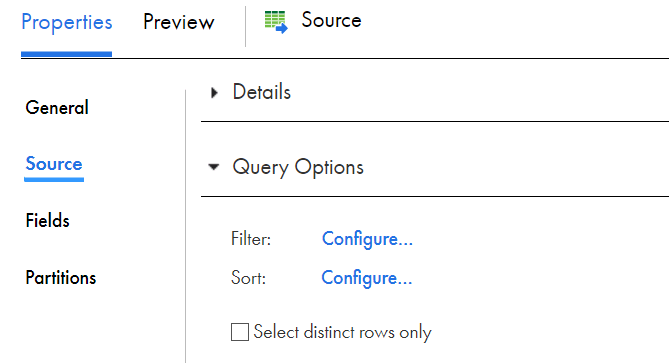
Filter and Sort options are not supported when a custom query is used as source.
Under Advanced tab of Source transformation
- You can pass the Pre SQL and Post SQL commands.
- Adjust Tracing Level
1.2 Flat Files as Source Object
When the connection type is a Flat File connection, you could select the source type as
- Single Object: A single flat file object can be selected as a source.
- File List: You can pass a filename with list of flat file names with same file structure to process all the files through a single source transformation. This is called Indirect File loading.
- Command: You can pass a script file as input which passes the source flat file name(s).
- Parameter: The source flat file name can be parameterized in mapping for which the value could be passed from a mapping task.
Filter and Sort options are not supported for Flat File connection type.
The properties in the source transformation varies as per the connection type selected.
1.3 Fields section in Source Transformation

- New fields can be added from the Fields section of source transformation. If the field is not present in the database object during the mapping run, the task fails.
- Existing fields can be deleted from the Fields section. During the mapping run the Integration service will not try to read the field from the database that is deleted in the source transformation.
- The fields can be sorted in the ascending order, descending order or existing Native order based on the field name.
- Source fields metadata can be modified (i.e. modifying the field’s datatype, precision and scale) from the Fields section by clicking on Options and select Edit Metadata.
- The changes in the source object fields can be synchronized by clicking the Synchronize button. You can choose between synchronizing All Fields or New Fields only.
- For Flat File sources, an additional field can be added which gives the source flat file name as value by selecting the Add Currently Processed Filename field in the Fields section.
1.4 Partitions section in Source Transformation
Partitioning enables the parallel processing of the data through separate pipelines.
There are two major partitioning methods supported in Informatica Cloud Data Integration.
- Key Range Partitioning
- Fixed Partitioning
The Key Range partitioning method is supported for relational sources. Fixed partitioning is supported for non-relational sources such as flat file sources.
For a detailed information about partitions, check out the article on Informatica Cloud Partitioning.
2. Filter Transformation in Informatica Cloud
Filter transformation is an active and connected transformation in Informatica Cloud. It is used to filter data out of the data flow based on a specified filter condition.
The filter condition defined in the filter transformation is an expression that returns either TRUE or FALSE. The default return value from filter transformation is TRUE. That means you can add a filter transformation in the mapping without any condition defined and it allows all the records pass through it.
Similarly, you can define filter condition as FALSE which acts as a logical stop of the flow of the mapping as no records will be passed further. This Helps while checking the logic of the mapping in case of some problems.
2.1 Types of Filter Conditions in Informatica Cloud
In Filter transformation, filter conditions can be defined in three different types
- Simple
- Advanced
- Completely Parameterized
Filter conditions are case sensitive. You can use the following operators in filter transformation
- = (equals)
- < (less than)
- > (greater than)
- < = (less than or equal to)
- > = (greater than or equal to)
- ! = (not equals)
2.2 Simple Filter Condition
You can create one or more simple filter conditions. A simple filter condition includes a field name, operator, and value.
When you define more than one simple filter condition, the mapping task evaluates the conditions in the order that you specify using the AND logical operator.
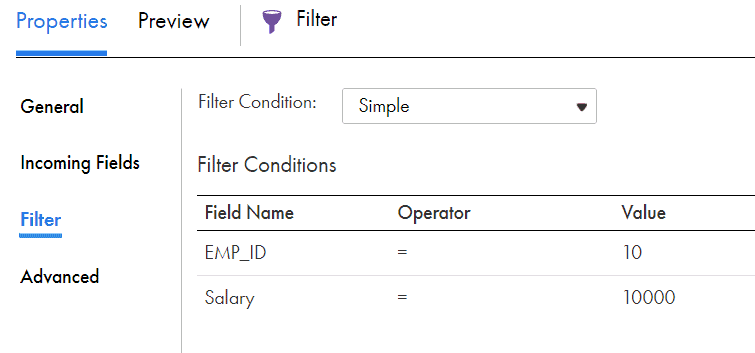
In the above example, the filter condition will be treated as
DEP_ID = '10' and SALARY = ‘10000’2.3 Advanced Filter Condition
You can use an Advanced filter condition to define a complex filter condition. When you configure an advanced filter condition, you can incorporate multiple conditions using the AND or OR logical operators.
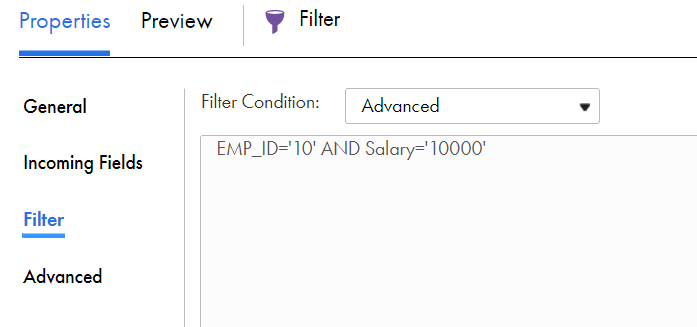
When you change the filter condition type from simple to advanced, the Mapping Designer automatically converts the simple filter conditions to the advanced filter condition.
2.4 Parametrization of Filter condition
The filter condition could be completely parameterized in filter transformation by creating an Input parameter of type expression for which value could be passed during the mapping runtime or from mapping task.
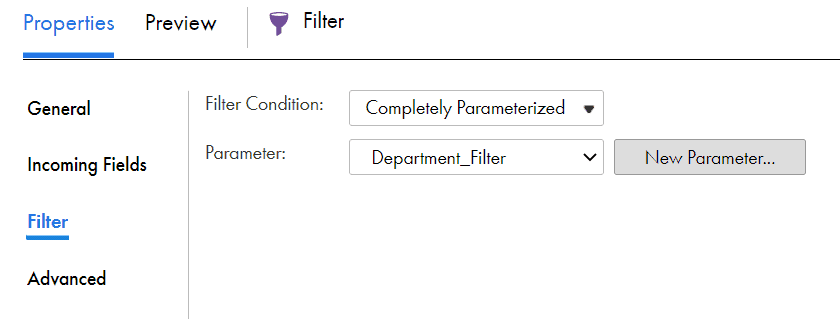
Additionally, the field name and the value of the field could be parameterized and used in the simple and advanced filter conditions.
$DEP_ID$ = $DEP_Value$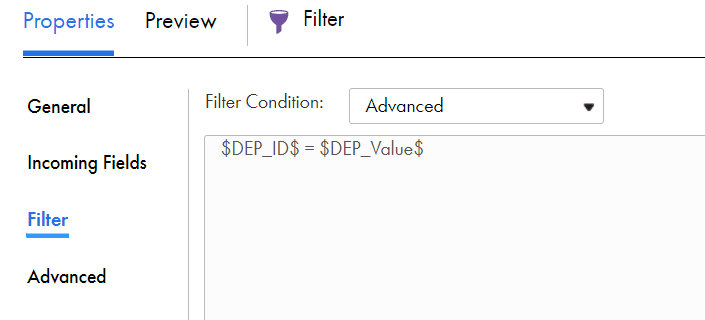
In the above example, we have created two input parameters. One of type Field and other of type String.
When the parameters are used in filter condition, the simple filter condition to advanced filter condition conversion is not supported. You need to manually enter the condition.
2.5 Filter Performance Tuning
- Use the Filter transformation as close to the source as possible in the mapping. This will reduce the number of rows to be processed in the downstream transformations.
- In case of relational sources, if possible use the filter condition in the source transformation. This will reduce the number of rows to be read from the source.
3. Router Transformation in Informatica Cloud
Router transformation is an active and connected transformation in Informatica Cloud. It is similar to filter transformation except that multiple filter conditions can be defined in the router transformation. Where as in filter transformation you can specify only one condition and drops the rows that do not satisfy the condition.
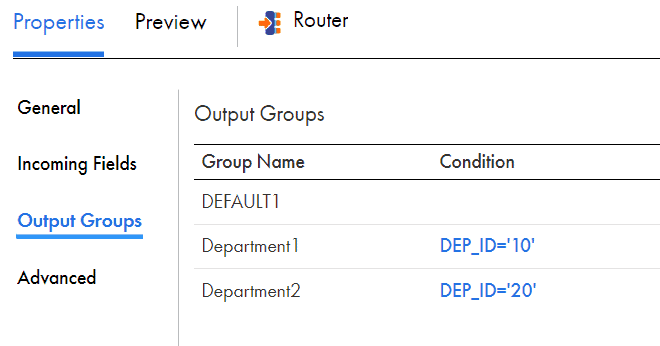
3.1 Output Groups in Router Transformation
You can create multiple groups in router transformation with each having its own filter condition. In the below example you can see multiple groups defined for each department.
For each output group defined, a new data flow will be created which can be passed to downstream transformations as shown below.
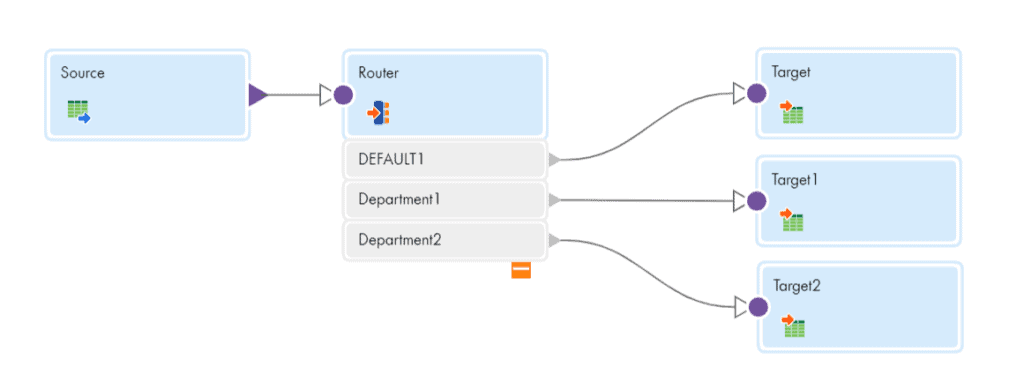
3.2 Default Group in Router Transformation
By default, there will be a DEFAULT group that comes with in router transformation. The rows which do not satisfy any filter condition are passed through the default group. In our example, departments with ID other then 10 and 20 will be passed through DEFAULT group.
Router filter conditions are not if and else. If a rows satisfies the filter condition in multiple groups, the router transformation passes data from all the output groups that satisfy the condition.
3.3 Filter Condition types in Router Transformation
The filter condition types supported in Router transformation is similar to that what we have already discussed in Filter transformation. You can define a simple or advanced filter condition or completely of partially parameterize the filter condition based on the requirement.
4. Expression Transformation in Informatica Cloud
Expression transformation is a passive and connected transformation in Informatica Cloud. Expression transformation is used for row-wise manipulation. The Expression transformation accepts the row-wise data, manipulates it, and passes it to the downstream transformation.
4.1 Expression Transformation Use Cases
Expression transformation can be used to
- concatenate or split incoming field values
- create new fields
- Insert hard coded values into a field
- perform non-aggregate calculations
4.2 Expression Transformation Field Types
In Expression transformation new fields of below type can be created.
- Output Field
- Variable Field
- Input Macro Field
- Output Macro Field
Create an Output Field to perform certain operation for each record in the dataflow and pass it to the downstream transformation.
Create a Variable Field for calculations that you want to use within the transformation. The variable fields are not passed to the downstream transformations. They are usually used to hold a temporary value and can be used directly in the output fields created in the expression transformation.
4.3 Expression Macros
Informatica Cloud supports Expression Macros which allow you to create repetitive and complex expressions in mappings. Use Input and Output Macro Field types to implement expression macros.
An Input Macro Field represent the data of multiple source fields. An Output Macro Field represents the calculations that you want to perform on each input source field.
For example, you need to trim spaces in source fields data before loading into target. To implement this, you need to apply the TRIM logic for each field separately. Using expression macros, this can be implemented using one Input Macro field and Output Macro field.
To learn more, check out the detailed article on Expression Macros in Informatica Cloud.
5. Sorter Transformation in Informatica Cloud
Sorter transformation is an active and connected transformation in Informatica Cloud. Sorter transformation is used to sort the data based on incoming fields either in ascending or descending order.
5.1 Sorter Transformation Properties
When you configure a Sorter transformation, you define Sorter properties on the following tabs of the Properties panel:
- Sort tab: Define the Fields and Sort order on which data coming from upstream transformation should be sorted.
- Advanced tab: Define advanced properties like Distinct of Sorter transformation.
5.2 Configuring Sort Fields and Sort Order
When you specify multiple sort conditions, the mapping task sorts each condition sequentially. The mapping task treats each successive sort condition as a secondary sort of the previous sort condition. You can modify the order of sort conditions.
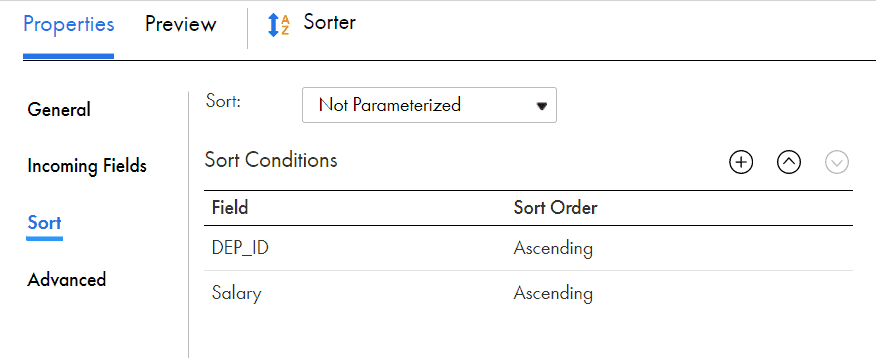
In the above example, the records are sorted department wise first and later the records in each department are sorted based on salary.
5.3 Parameterizing the Sort Condition
Informatica Cloud supports parameterizing the sort condition in the mapping where you can define the sort fields and the sort order when you run the mapping or when you configure the mapping task.
5.4 Sorter Transformation Advanced Properties
Sorter transformation can also remove duplicate records from the incoming data. This can be enabled by selecting the Distinct option in the Advanced tab.
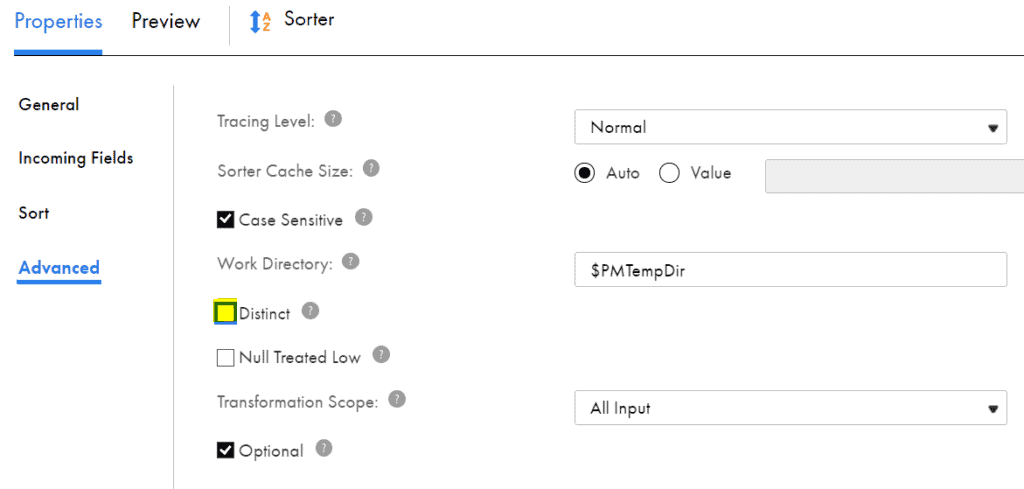
The other properties that can be configured from the Advanced tab of sorter transformation are
- Case Sensitive: When enabled, the transformation sorts uppercase characters higher than lower case characters.
- Null Treated Low: Treats a null value as lower than any other value. For example, if you configure a descending sort condition, rows with a null value in the sort field appear after all other rows.
6. Aggregator Transformation in Informatica Cloud
Aggregator transformation is an active and connected transformation in Informatica Cloud. It is Used to perform aggregate calculations such as sums, averages, counts on groups of data.
6.1 Aggregator Transformation Properties
When you configure a Aggregator transformation, you define Aggregator properties on the following tabs of the Properties panel:
- Group By tab – Configure Group by Fields to define how to group data for aggregate expressions.
- Aggregate tab – Configure an Aggregate field to define aggregate calculations. You can use aggregate functions, conditional clauses and non-aggregate functions in aggregate fields.
- Advanced tab – To improve job performance, you can configure an Aggregator transformation to use sorted data. To configure it, on the Advanced tab, select Sorted Input
For example, when you wanted to calculate average salary of employees department wise,
select the department_id as Group By Field under Group By tab.
Create new aggregate field Avg_Salary and assign value as AVG(Salary) under Aggregate tab of Aggregator transformation.
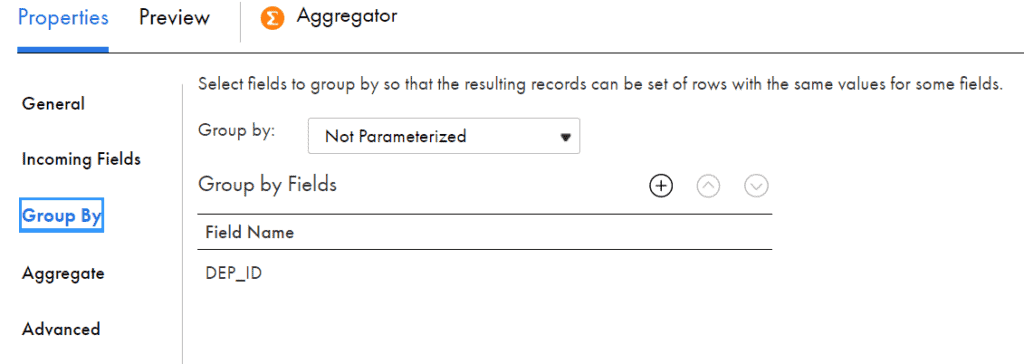
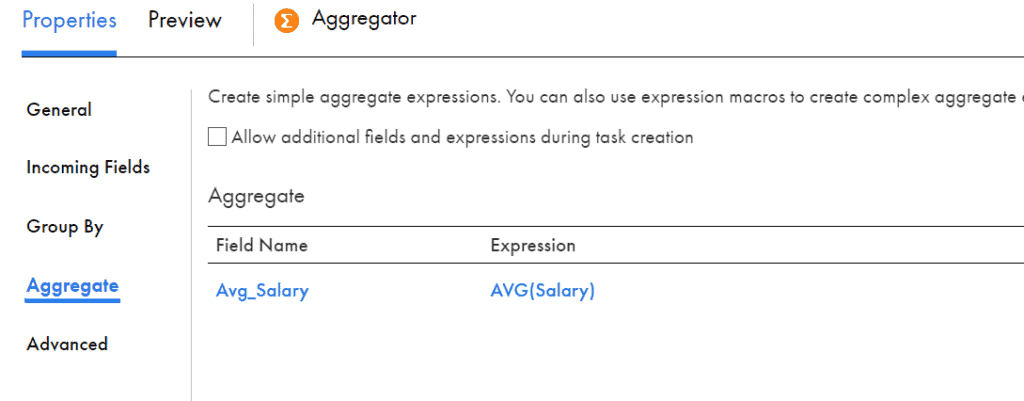
Aggregator transformation is used to remove duplicates. This can be achieved when all the incoming fields are selected as Group By fields
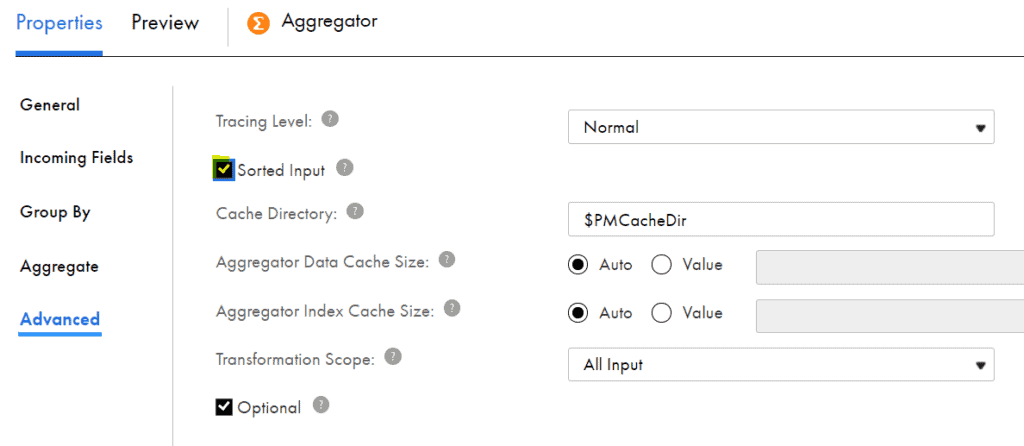
6.2 Types of Aggregator Cache
Aggregator uses Index Cache and Data Cache
- Index Cache stores group values as configured in Group By Fields.
- Data Cache stores calculations based on Group By Fields.
6.3 How Sorted Input increases Performance in Aggregator?
When sorted input option is not enabled, the aggregator does not know when a group by field would come. So it holds the entire data and process record by record.
When Sorted Input is enabled, the group by fields are expected to be sent in a sorted order. It creates an Index cache on the first group by fields defined and starts adding their values in the data cache.
When the task reads data for different group, it performs aggregate calculations for the cached group, and then continues with the next group.
There by a set of data is already forwarded from aggregator to the downstream transformation while it is making aggregate calculations on the next group.
6.4 What happens when no fields are selected as Group By Fields in Aggregator?
When no fields are selected as Group By field, aggregator creates a default index and it will keep on overriding each record in the data cache. So finally, the last record of the data will be sent as output.
7. Sequence Transformation in Informatica Cloud
Sequence Generator transformation is a passive and connected transformation in Informatica Cloud. It is used to generate sequence of numeric values.
Use Sequence generator transformation to
- Generate sequence of unique numbers
- Generate a cyclic sequence of numbers
7.1 Sequence Generator Fields
The Sequence Generator transformation has two output fields, NEXTVAL and CURRVAL of datatype big int. No other ports can be added and default ports can’t be removed.
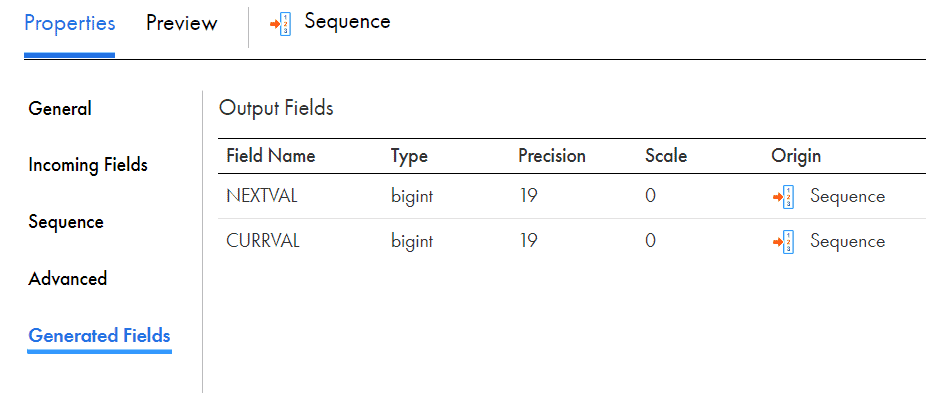
Use the NEXTVAL field to generate a sequence of numbers based on the Initial Value and Increment By properties.
CURRVAL port value is always NEXTVAL+1. If you connect only the CURRVAL port without connecting the NEXTVAL port, then the mapping task generates a constant value for each row.
7.2 Sequence Generator Types in Informatica Cloud
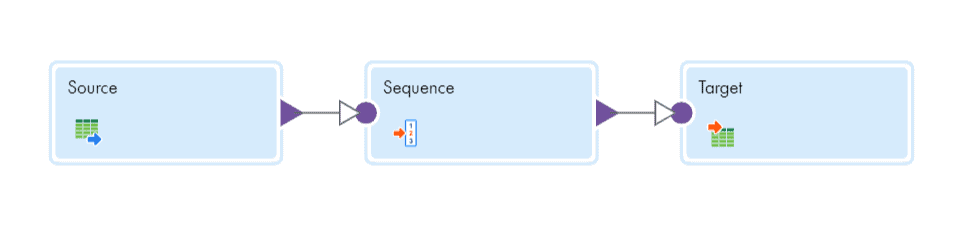
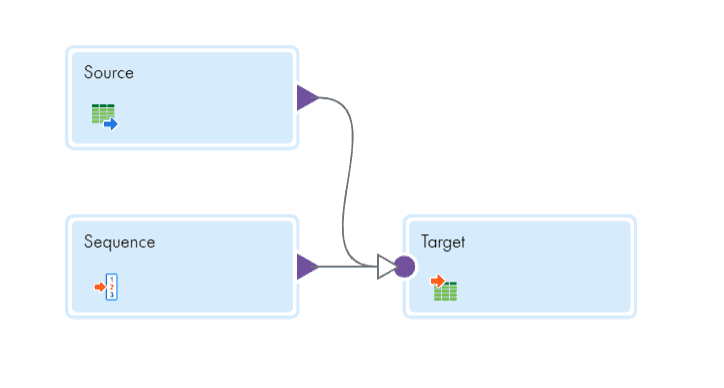
Sequence generator can be used in two different ways in Informatica cloud. One with Incoming fields disabled and the other with incoming fields not disabled.
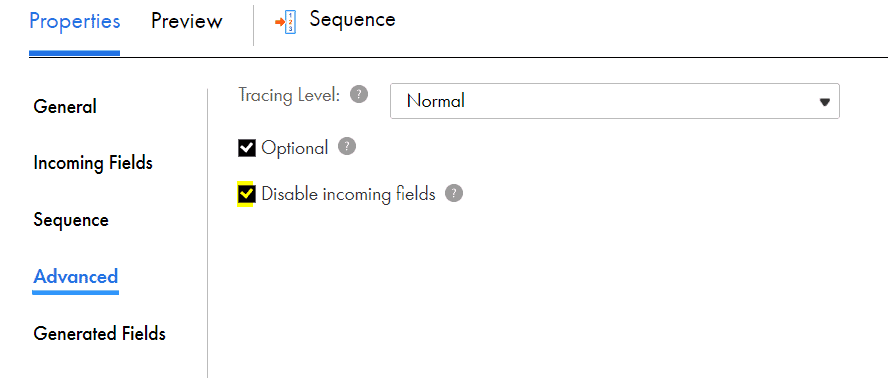
In order to disable the incoming fields, navigate to Advanced tab of sequence generator and check the Disable incoming fields option.
The difference between the sequence generator with incoming fields enabled and disabled is when NEXTVAL field is mapped to multiple transformations
- Sequence generator with incoming fields not disabled will generate same sequence of numbers for each downstream transformation.
- Sequence generator with incoming fields disabled will generate Unique sequence of numbers for each downstream transformation.
To generate the same sequence of numbers when incoming fields are disabled, you can place an Expression transformation between the Sequence Generator and the downstream transformations to stage the sequence of numbers.
7.3 Sequence Generator Properties
- Initial Value: It is the first value that is generated by the sequence generator transformation. The default value is 1.
- Increment By: – This is the number by which you want to increment the sequence values. The default value is 1.
- End value: It is the maximum value that the sequence generator transformation generates.
- Cycle: If enabled, after reaching the end value, the transformation restarts from the initial value. By default, the option is disabled. If disabled and the sequence reaches the end value specified with rows still to process, the task would fail with overflow error.
- Cycle Start Value: Start value you want the sequence generator to use when cycle option is enabled. Default is 0.
- Number of Cached Values: The default value is 0. When the value is >0, the mapping task caches the number of sequential values specified and updates the value in repository. Once the cached values are used up it will again go to the repository. If there are unused sequence numbers in the cached values, the task will discard them.
Use this option when multiple partitions use the same Sequence Generator at the same time to ensure each partition receives unique values.
The disadvantage of using Number of Cached Values greater than zero are:- Accessing the repository multiple times during the session.
- Discarding of unused cached values, causing discontinuous sequence numbers
- Reset: If enabled, the mapping task generates values based on the original Initial Value for each run. Default is disabled.
Related Article: Shared Sequences in Informatica Cloud
Subscribe to our Newsletter !!
8. More Transformations…….
- Lookup Transformation
- Joiner Transformation
- Union Transformation
- Normalizer Transformation
- Hierarchy Parser Transformation
- Hierarchy Builder Transformation
- Transaction Control Transformation
- WebServices Transformation
Related Posts:








Great documentation !!
Thank you Rani!!👍
Totally loved your content!
Thank you!!