
1. Introduction
Informatica offers several performance tuning and optimization techniques. Partitioning is one such performance tuning option offered in Informatica cloud which enables you to optimize the performance of mapping tasks.
In this article, let us understand the Partitioning options available in Informatica Cloud Data Integration, its advantages and limitations and how it differs from partitioning available in Powercenter.
2. How Partitioning works in Informatica Cloud?
The Data Transformation Manager (DTM) process is the operating system process that the Data Integration Service creates to carry out session tasks by creating and managing threads.
For each Flow Run Order in a mapping, several threads are created depending on the design of the mapping and the transformations used.
The following shows a simple mapping in Informatica Cloud with no partitioning enabled.

With no partitioning enabled the mapping is considered to running on a single partition. In this case DTM process creates one reader, one transformation, and one writer thread to process the data.
- The reader thread controls how the Data Integration Service process extracts source data.
- The transformation thread controls how the Data Integration Service process processes the data.
- The writer thread controls how the Data Integration Service process loads data into the target.
With the Partitioning enabled, you can select the number of partitions for the mapping. The DTM process then creates a reader thread, transformation thread and writer thread for each partition allowing the data to be processed concurrently, thereby reducing the execution time of the task.
Partitioning is nothing but enabling the parallel processing of the data through separate pipelines.
Partitions can be enabled by configuring the Source transformation in mapping designer. When the partitions are configured in Source transformation, partitioning occurs throughout the mapping.
3. Types of Partitions supported in Informatica Cloud
There are two major partitioning methods supported in Informatica Cloud Data Integration.
- Key Range Partitioning
- Fixed Partitioning
The Key Range partitioning method is supported for relational sources and Fixed partitioning is supported for non-relational sources such as flat file sources.
3.1 Key Range Partitioning
The Key Range Partitioning distributes the data into multiple partitions based on the partitioning key selected and range of the values defined for it. You must select a field as a partitioning key and defined the start and end ranges of the value.
The data types supported by Key Range Partitioning are
- String
- Number
- Date/time
To enable the key range partitioning
- Navigate to Partitions tab of a relational source in Source transformation.
- Select Key Range as Partitioning type from drop down. The default value will be None.
- Once key range partitioning type is selected, you will be prompted to select a source field as Partitioning Key.
- After selecting the Partitioning Key, select the required number of partitions and specify the start and end range values for each partition accordingly.
In the below example with a test data of million records of employee data, the Partitioning Key is selected on the field EMPLOYEE_ID. There were three partitions created and the start and end range values of each partition are as shown below.
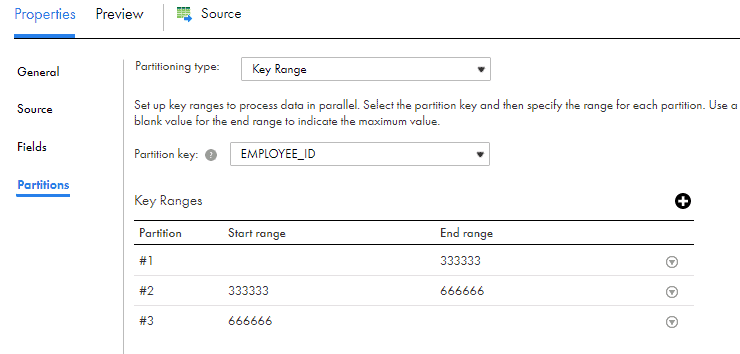
Use a blank value for the start range to indicate the minimum value. Use a blank value for the end range to indicate the maximum value.
Without the partitioning enabled, all the 1 million records are read and processed in a single pipeline.
With Partitioning enabled, three different pipelines are created and the data is read and processed concurrently. Informatica creates three different queries based on partitions and values range specified as below.
SELECT HR.EMPLOYEE.EMPLOYEE_ID, HR.EMPLOYEE.FIRST_NAME, HR.EMPLOYEE.LAST_NAME, HR.EMPLOYEE.EMAIL, HR.EMPLOYEE.PHONE_NUMBER, HR.EMPLOYEE.HIRE_DATE, HR.EMPLOYEE.JOB_ID, HR.EMPLOYEE.SALARY, HR.EMPLOYEE.MANAGER_ID, HR.EMPLOYEE.DEPARTMENT_ID FROM HR.EMPLOYEE WHERE HR.EMPLOYEE.EMPLOYEE_ID < 333333SELECT HR.EMPLOYEE.EMPLOYEE_ID, HR.EMPLOYEE.FIRST_NAME, HR.EMPLOYEE.LAST_NAME, HR.EMPLOYEE.EMAIL, HR.EMPLOYEE.PHONE_NUMBER, HR.EMPLOYEE.HIRE_DATE, HR.EMPLOYEE.JOB_ID, HR.EMPLOYEE.SALARY, HR.EMPLOYEE.MANAGER_ID, HR.EMPLOYEE.DEPARTMENT_ID FROM HR.EMPLOYEE WHERE HR.EMPLOYEE.EMPLOYEE_ID >= 333334 AND HR.EMPLOYEE.EMPLOYEE_ID < 666666SELECT HR.EMPLOYEE.EMPLOYEE_ID, HR.EMPLOYEE.FIRST_NAME, HR.EMPLOYEE.LAST_NAME, HR.EMPLOYEE.EMAIL, HR.EMPLOYEE.PHONE_NUMBER, HR.EMPLOYEE.HIRE_DATE, HR.EMPLOYEE.JOB_ID, HR.EMPLOYEE.SALARY, HR.EMPLOYEE.MANAGER_ID, HR.EMPLOYEE.DEPARTMENT_ID FROM HR.EMPLOYEE WHERE HR.EMPLOYEE.EMPLOYEE_ID >= 666667The final source/target results are as below

In my testing to load a million records from an Oracle database into a flat file, it took 28 seconds without partitioning. With partitioning enabled, it took 20 seconds to load the data. If there is some transformation logic also involved, the difference would be much higher as that would also be processed concurrently in three different pipelines.
It can also be understood that higher the number of records, higher the performance boost that can be obtained from partitioning.
3.2 Fixed Partitioning
Fixed Partitioning can be enabled for sources which are not relational or support key range partitioning.
To enable Fixed partitioning
- Navigate to Partitions tab of a non-relational source in Source transformation.
- Select Fixed as Partitioning type from drop down. The default value will be None.
- Once key range partitioning type is selected, you will be prompted to select the number of partitions in the mapping.
- Enter the number of desired partitions.
In the below example, three partitions are created on a flat file source with million records.

In my testing it took 3 minutes, 25 seconds to load a million records from a flat file into an oracle table. With partitioning enabled, it took 1 minute, 39 seconds to load the data.
The difference in processing time is clearly evident in this case.
4. Guidelines to Informatica Cloud Partitioning
- The maximum number of partitions that could be specified is 64.
- Consider the number of records to be passed in the mapping to determine an appropriate number of partitions for the mapping.
- For a small number of records, partitioning might not be advantageous.
- If the mapping includes multiple sources, specify the same number of partitions for each source so that data is processed in consistent pipelines.
- Partitioning is not supported when mapping uses a parameterized source or source query.
- Partitioning is not supported when mapping includes Hierarchy Parser or Web services transformation.
- When a Sorter transformation is in a mapping with partitioning enabled, the task sorts data in each partition separately.
- Sequence numbers generated by Normalizer and Sequence Generator transformations might not be sequential for a partitioned source, however they are unique.
- Parameters cannot be used for key range values.
5. Informatica Cloud Partitioning vs Informatica Powercenter Partitioning
- Informatica Powercenter offers a wide range of partitioning options compared to Informatica Cloud Data Integration. The partitioning types supported in Powercenter are
- Database partitioning
- Round-robin
- Pass-through
- Hash auto-keys
- Hash user keys
- Key range
- Partition points mark the boundaries between threads in a pipeline and divide the pipeline into stages. Informatica Powercenter supports partition points at various transformations in the mapping. When you add partition points, you increase the number of transformation threads, which can increase session performance. However in Informatica Cloud, you should use only default partition points created by data integration service.
- When you create a partition point at various transformations, the Workflow Manager in Powercenter sets the default partition type. You can change the partition type depending on the transformation type. In Informatica Cloud, partitioning is allowed only at source transformation end.
- Informatica Powercenter shows visually the details of default partition points and pipeline stages in a mapping in workflow manager. There is no visual representation of default partition points provided in Informatica Cloud.
6. Conclusion
Partitioning is a great way to improve the task performance when working with large amounts of data. At present Informatica Cloud offers only two partitioning types and only on Source transformation which makes it easy to work with as you need not worry about selecting an optimal partitioning type from a broad list of partitioning types at various partition points. Just make sure an optimal number of partitions are selected for the amount of data you are processing and you are good to go.
There is a lot of catching up to do for Informatica cloud in terms of partitioning options compared to Powercenter and hope to see them getting added in future releases.
Check out our Instagram Posts on Informatica Cloud Partitioning



Hello Thanks for the explanation.
One doubt-When we want to upload big size file (File >1 GB) on Amazon S3 we Files can be uploaded in multiple parts into Amazon S3 bucket using the Amazon S3 V2 connector. The Amazon S3 connector works on ‘pass-through partitioning’ and allows a file to be uploaded in multiple parts when using Amazon S3 as a target.
But is it possible when we are using Custom Queries on the Source Level?Like I am using Source query to fetch the details from the table and loading the .csv and .control files to S3 from that mapping
Currently Partitioning is not supported when using custom query in source transformation in IICS.
Hi i ahve scenario like this,
I am reading data from 3 diff regions (mysql is the src database) and merging thru union and finally loading into Oracle tgt.In this case i need to give same partitions across all 3 src regions ?
Yes, if the mapping includes multiple sources, specify the same number of partitions for each source so that data is processed in consistent pipelines.
Hi,
Is there a possibility for dynamic partitioning in Informatica cloud?
No
Also, can you please share an example on how to use Key Range partitioning using string data type?
It seems to be not supported currently. Alternatively you can assign a unique number for each key value of the string field on which you want to partition and use that value while defining the Key Range partitioning.