
1. Introduction to Hierarchy Parser Transformation
Informatica Cloud supports reading JSON and XML files through Hierarchy Parser transformation in Cloud Mappings. The Hierarchy Parser transformation reads XML or JSON (hierarchical input) data from the upstream transformation and provides relational output to the downstream transformation.
A Hierarchical schema needs to be created and associated with Hierarchy Parser in order to use the transformation.
2. Hierarchical schema
A Hierarchical Schema defines the structure of the file that a Hierarchy Parser transformation converts into relational output.
If the input passed to the Hierarchy Parser and the Hierarchical Schema associated with it does not match, the data cannot be converted as expected.
Let us discuss in detail how to read JSON file using the hierarchical schema and hierarchy parser transformation in Informatica Cloud.
3. Reading a simple JSON file as input in the mapping
Consider the following as the source JSON file data which we want to read through Informatica Cloud.
Contents of author.json file.
[
{
"AUTHOR_UID": 1,
"FIRST_NAME": "Fiona",
"MIDDLE_NAME": null,
"LAST_NAME": "Macdonald"
},
{
"AUTHOR_UID": 2,
"FIRST_NAME": "Gian",
"MIDDLE_NAME": "Paulo",
"LAST_NAME": "Faleschini"
},
{
"AUTHOR_UID": 3,
"FIRST_NAME": "Laura",
"MIDDLE_NAME": "K",
"LAST_NAME": "Egendorf"
}
]Step1: Create a template file for Hierarchical Schema
By going through source data we can see that file contains array of author details. Each author element in the array consists of 4 attributes – AUTHOR_UID, FIRST_NAME, MIDDLE_NAME, LAST_NAME and their corresponding values.
Based on this we can create a sample template with only one author element in the array as below and save as author_template.json file.
[
{
"AUTHOR_UID": 999,
"FIRST_NAME": "XXXXXX",
"MIDDLE_NAME": "XXXXX",
"LAST_NAME": "XXXXXX"
}
]Understanding your source structure is important. The same source JSON file can also be used as a template file. But I just want to show the simple structure we defined as template can handle any number of author’s details present in source file.
Step2: Create a Hierarchical Schema
Login to Data Integration Service and click New from the left side menu.
Click on Components, select Hierarchical Schema and click Create.
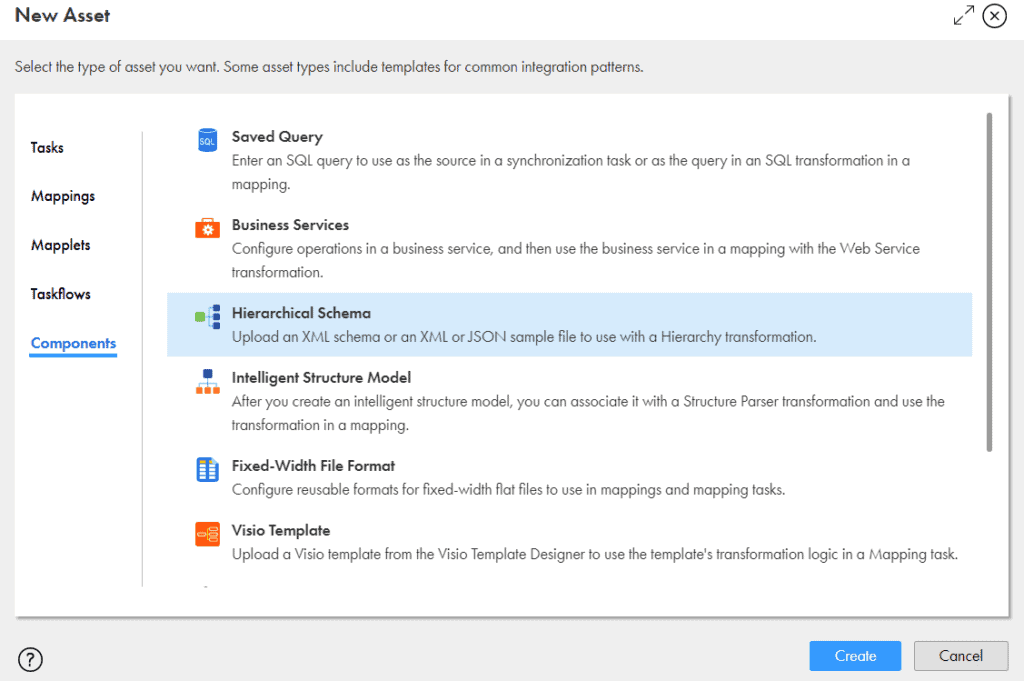
Enter the Name as Author_Hierarchical_Schema and Upload the JSON file we created as template as the Sample Schema file and Save it.
Step3: Preparing the Source file for the mapping
The author.json file which we want to read through IICS mapping cannot be passed directly to Hierarchy Parser transformation.
We need to create a text file with the source filename along with directory location and use this file as source in source transformation.
Contents of JSON_File.txt file
PATH
C:\IICS\author.jsonPATH represents the field name and the C:\IICS\author.json represents a row value.
Step4: Create a Mapping to read JSON file
I. Configuring Source transformation
Select the JSON_File.txt as the source file in Source transformation.

II. Configuring Hierarchy Parser transformation
Drag and drop a Hierarchy Parser transformation into mapping canvas.
In the Input Settings, select the Input Type as File and the select the Hierarchical Schema we have created in step2.

Select the Buffer mode when the JSON/XML data is in the incoming source column. Select the File mode when the JSON/XML data is in a file.
In our example we are reading the JSON data in a file, hence File mode is selected.
Map the source transformation to the Hierarchy Parser after this step.
Next in the Input Field Selection tab, map the incoming source field PATH to the Hierarchical Schema Input Field.

In the Field Mapping tab, click on rootArray and select Map all descendants
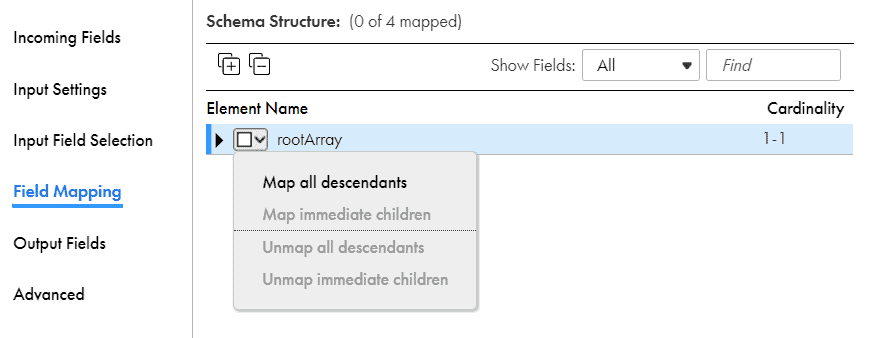
The fields from the hierarchy structure gets mapped to the relational fields as below.

The field mapping implies that now each author element from JSON file will be converted into a single relational output row with column name as AUTHOR_UID, FIRST_NAME, MIDDLE_NAME and LAST_NAME
III. Configuring Target transformation
Once the hierarchy parser is set up, pass the data into a target transformation.
Then a pop up arises and asking you to select the Output group. Select root and click OK.
We will discuss more about the output group selection in the further discussion below.

In the target transformation, select the flat file connection and create a dynamic target author_op.csv
The final mapping will be as below.

Save and run the mapping. The final output we get will be as below.
Contents of author_op.csv file
"author_uid","first_name","middle_name","last_name"
1,"Fiona",,"Macdonald"
2,"Gian","Paulo","Faleschini"
3,"Laura","K","Egendorf"Each element in the JSON file is converted into a row in the final output.
4. Reading multiple JSON files as input in the same mapping
Yes, we can read more than one JSON file at a time in the same mapping. But all the JSON files should share the same file structure.
Consider below as another JSON file with author details which we want to pass along with author.json file.
Contents of author2.json file.
[
{
"AUTHOR_UID": 4,
"FIRST_NAME": "Jan",
"MIDDLE_NAME": null,
"LAST_NAME": "Grover"
},
{
"AUTHOR_UID": 5,
"FIRST_NAME": "Jennifer",
"MIDDLE_NAME": null,
"LAST_NAME": "Clapp"
},
{
"AUTHOR_UID": 6,
"FIRST_NAME": "Kathleen",
"MIDDLE_NAME": null,
"LAST_NAME": "Petelinsek"
}
]In order to pass the second JSON file as input, add the filename in the JSON_File.txt file in the source transformation.
Contents of JSON_File.txtfile
PATH
C:\IICS\author.json
C:\IICS\author2.jsonThis is similar to the input file we use in Indirect File loading method. But we still select the Source Type as Single Object here instead of File List.
The rest of the procedure is same as we discussed in previous example.
The Source transformation passes input JSON files information and Hierarchy Parser reads and processes them one after the other.
The final output of the mapping will be as below appending the data from both JSON files.
Contents of author_op.csv file
"author_uid","first_name","middle_name","last_name"
1,"Fiona",,"Macdonald"
2,"Gian","Paulo","Faleschini"
3,"Laura","K","Egendorf"
4,"Jan",,"Grover"
5,"Jennifer",,"Clapp"
6,"Kathleen",,"Petelinsek"Similarly, we can pass any number of JSON files with same structure as input and read the output data in a single output file.
5. Reading a JSON file with multiple Output Groups
Consider the following as the source JSON file data which we want to read through Informatica Cloud.
Contents of author3.jsonfile.
[
{
"AUTHOR_UID": 1,
"FIRST_NAME": "Fiona",
"MIDDLE_NAME": null,
"LAST_NAME": "Macdonald",
"CONTACT DETAILS": [{
"Address": {
"Permanent address": "USA",
"current Address": "USA"
},
"phoneNumbers": {
"type": "office",
"number": "6666666"
}
}]
},
{
"AUTHOR_UID": 2,
"FIRST_NAME": "Gian",
"MIDDLE_NAME": "Paulo",
"LAST_NAME": "Faleschini",
"CONTACT DETAILS": [{
"Address": {
"Permanent address": "USA",
"current Address": "CAN"
},
"phoneNumbers": {
"type": "office",
"number": "7777777"
}
}]
},
{
"AUTHOR_UID": 3,
"FIRST_NAME": "Laura",
"MIDDLE_NAME": "K",
"LAST_NAME": "Egendorf",
"CONTACT DETAILS": [{
"Address": {
"Permanent address": "AUS",
"current Address": "USA"
},
"phoneNumbers": {
"type": "Home",
"number": "9999999"
}
}]
}
]Step1: Create a template file for Hierarchical Schema
By going through source data we can see that file contains array of author details. Each author element in the array consists of 5 attributes – AUTHOR_UID, FIRST_NAME, MIDDLE_NAME, LAST_NAME and CONTACT DETAILS.
Here the attribute “CONTACT DETAILS” itself is an another array which holds Address and PhoneNumbers details.
Let us not worry more about the structure now. We can identify the repetitive structure in the file which can be used as a Schema template file.
Contents of author_template2.json file.
[
{
"AUTHOR_UID": 1,
"FIRST_NAME": "Gian",
"MIDDLE_NAME": "Paulo",
"LAST_NAME": "Faleschini",
"CONTACT DETAILS": [{
"Address": {
"Permanent address": "USA",
"current Address": "CAN"
},
"phoneNumbers": {
"type": "office",
"number": "7777777"
}
}]
}
]Step2: Create a Hierarchical Schema
Create a Hierarchical Schema similarly as discussed in the first example and select the Schema template file we created in the earlier step.
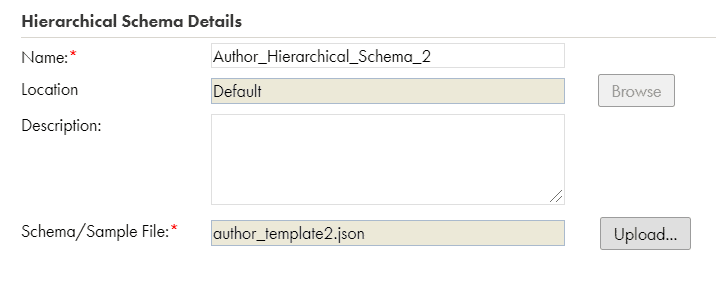
Step3: Preparing the Source file for the mapping
Create a text file with the source JSON filename along with directory location.
Contents of JSON_InputFile.txt file
PATH
C:\IICS\author3.jsonStep4: Create a Mapping to read JSON file
I. Configuring Source transformation
Select the JSON_InputFile.txt as the source file in Source transformation.
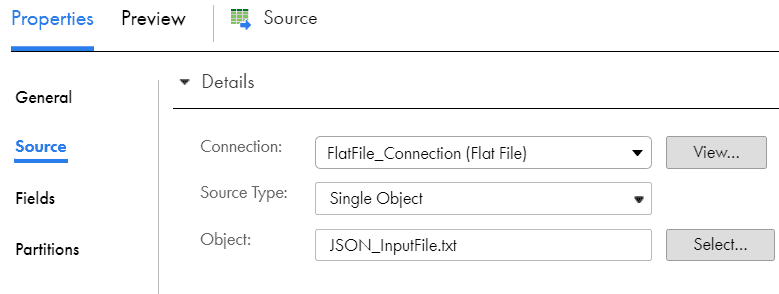
II. Configuring Hierarchy Parser transformation
Drag and drop a Hierarchy Parser transformation into mapping canvas.
In the Input Settings, select the Input Type as File and the select the Hierarchical Schema Author_Hierarchical_Schema_2.
Next in the Input Field Selection tab, map the incoming source field PATH to the Hierarchical Schema Input Field.
In the Field Mapping tab, click on rootArray and select Map all descendants
The fields from the hierarchy structure gets mapped to the relational fields as below.
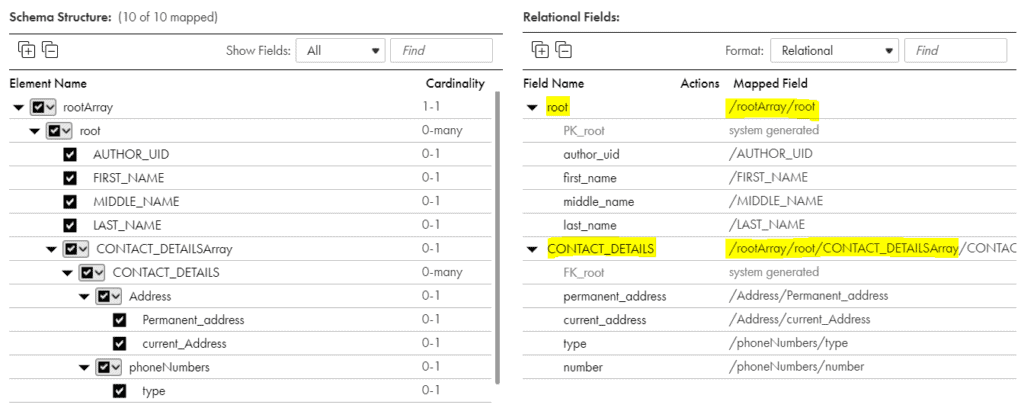
Here we can see that the relational fields are divided into two groups.
Group1 contains the root(author) details which is represented as /rootArray/root
Group2 contains the Contact_Details which is represented as /rootArray/root/CONTACT_DETAILSArray/CONTACT_DETAILS
So the Contact_DetailsArray is identified under root which in turn stays in the rootArray as expected.
There is also a system generated field PK_root and FK_root in group1 and group2 respectively now.
These system-generated fields are used to join the author data with contact_details data using the primary key-foreign key concept.
When there are multiple output groups, they will be definitely linked together through Primary Key – Foreign Key relationship through system-generated fields.
III. Mapping Multiple output groups to Expression transformation
Now when you try to map the data from Hierarchy Parser transformation, a popup shows up two different output groups.
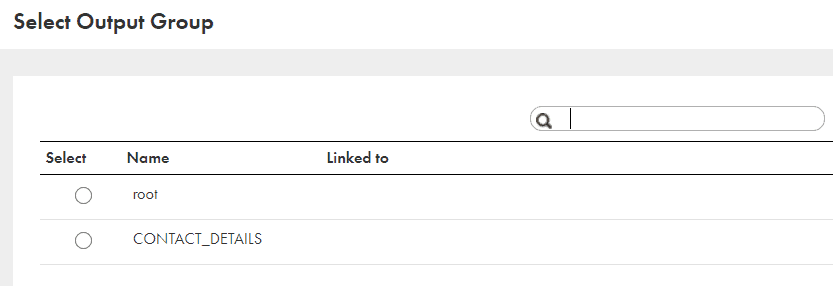
This implies that we cannot read Output Groups root and Contact_Details information in a single flow. They have to be read and joined separately.
Map each group to a different expression transformation.
Drag and drop a Joiner transformation into the canvas and map the output from both expression transformations.
Join them based on the condition PK_root = FK_root
Don’t miss to check the Sorted Input option in Advanced tab else the data cannot be joined.
V. Configuring Target transformation
Map the output from joiner to target transformation.
Create a dynamic flat file target author_contactdetails.csv and save the mapping.
The final mapping will be as below.
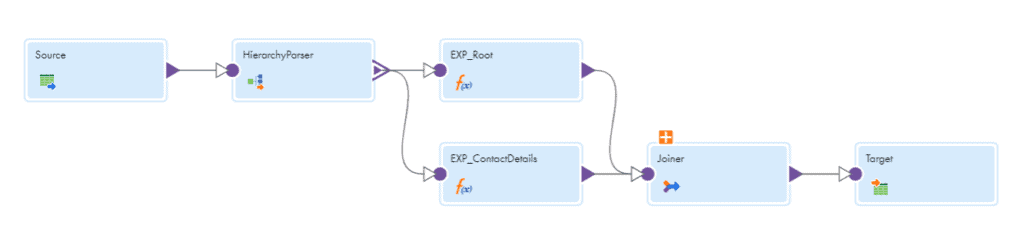
Run the mapping and the final output we get will be as below.
Contents of author_contactdetails.csv file
"PK_root","author_uid","first_name","middle_name","last_name","FK_root","permanent_address","current_address","type","number"
1,1,"Fiona",,"Macdonald",1,"USA","USA","office","6666666"
2,2,"Gian","Paulo","Faleschini",2,"USA","CAN","office","7777777"
3,3,"Laura","K","Egendorf",3,"AUS","USA","Home","9999999"The PK_root and FK_root fields can be avoided in the output by excluding them in target transformation.
You can find examples for parsing JSON file with multiple output groups in our articles How to read Mapping Configuration Task metadata in Informatica Cloud (IICS)? And How to read Mapping metadata in Informatica Cloud (IICS)?
6. Conclusion
These are the different aspects of processing a JSON file in Informatica Cloud. Processing an XML file also follows similar steps.
We can also create a JSON or XML file in Informatica Cloud. But let’s leave that discussion to a separate article.
Subscribe to our Newsletter !!
Related Articles:

Learn how to create a JSON file in IICS using Hierarchy Builder transformation. Understand how to prepare source data to create JSON file

Learn how to read a Fixed-Width file in Informatica Cloud. Understand how to create and use a Fixed-Width File Format component.

Understand how to trigger IICS tasks from command line using RunAJob utility and its requirements and setup process.


Nice Article Kudos ,keep posting ..!!
Thanks Omkar. Glad it helped!!
Nice one, please keep adding IICS tutorials.
Thanks Subhankar. More articles coming!!
All the articles are really helpful. Appreciate your true efforts towards the community!!
Thank you. Glad it helped!!
Well Explanation…Keep you good work!!! It is really helping us while working on the actual senarios.
Thanks Kishore. Glad it helped!!
Very nice Explanation!!..Thanks
Thanks Venkat!!
this is very helpful and so simple to understand for the new person to IICS
Thanks Ashish. Glad it helped!!
Does the JSON or XML file have to be local to the Secure Agent for the Hierarchy Parser transformation to work? My XML files are on AWS S3 bucket.
The process to read XML or JSON file from S3 bucket is different. Here is the Informatica article I found.
I am able to process a JSON file using this method. I will try to publish a detailed article on the same soon.
Hi, Refer this article published on our site. Feel free to share your feedback!!
Very good explaination 🙂
Thank you Shital!!
very happy to find your website. I am a beginner in IICS and extremely easy explained articles..Keep posting bro!!
Thanks Divya. Appreciate your feedback!!
You are the only and the best blog on IICS ! kudos ! keep posting !! You’re becoming famous
Thank you Shefali!!👍
Hi ,
Can we have JSON file name as column against the records from that JSON, in CSV as well?Is that doable from the same mapping?
Great post ..You have no idea how many people will benefit from this ..Thanks
Thank you!!😊
You guys are awesome. All your blogs are reflect a good developer perspective. Keep it up guys and thak you very much for all you content
Thanks Naman!!
Awesome . Nice explanation and presentation.
Pls do more programs . This is really helping a lot .
Thanks Mahesh for the feedback..Glad it helped!!
This is a brilliant explanation and in details, thanks much.
Thanks Abdul!!