Let’s discuss a step by step guide to read mapping metadata in Informatica Cloud.
Its needs a onetime setup at your end and I will guide you through that process. This will also act as an Auto review accelerator tool which reads metadata of IICS Mappings.
1. Introduction
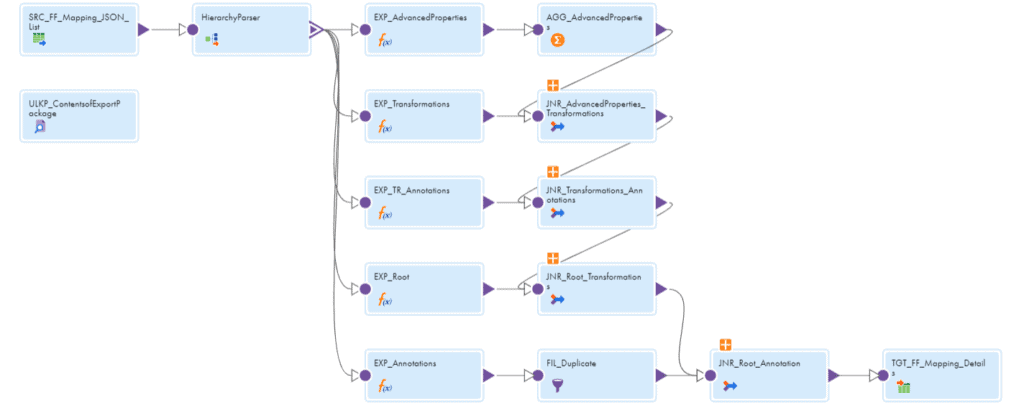
Here we will be using the zip file exported from IICS as an input to read the metadata. Next a script to extract the JSON files from the exported zip. A mapping to read the JSON files using a Hierarchy Parser and generate a report with required metadata details.
I have explained briefly on how to fetch the zip file, what would be the contents of the zip file and how to build a script to fetch the JSON files here.
Here we will be discussing on the mapping development to read metadata of IICS Mappings.
2. Steps involved in Mapping Development
If you have already read my article on How to read MCT metadata in Informatica cloud, the approach is similar.
But there are a lot of field segments available in Mapping JSON file compared to MCT JSON file.
Let’s discuss the important field segments required to us.
Don’t worry looking at the mapping size. I will break down everything in an easy manner to understand.
Moreover, if you feel that some metadata information is not necessary to you, it can be excluded from the mapping.
First thing first, let’s start from source.
2.1. Source transformation
The Source transformation reads a flat file containing the list of all the mapping JSON files as a source.

2.2. Hierarchy Parser transformation
- The Hierarchy Parser transformation reads the JSON files one after the other and provides a relational output.
- A Hierarchy Schema needs to be defined and imported into the Hierarchy Parser transformation.
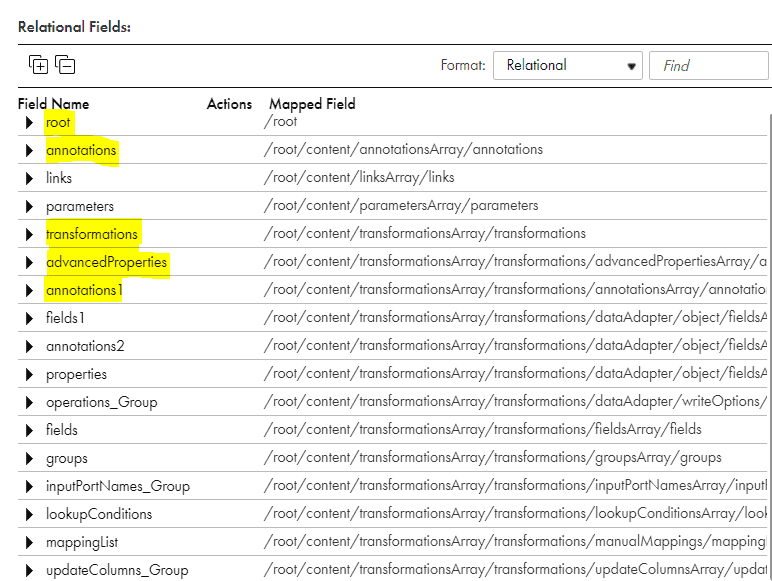
- The Hierarchy Parser parses the JSON input into below relational format.
- As discussed already there is a lot of information to consume from the metadata as shown below. We will be focusing on the field segments highlighted below in the article. They all are related by Primary Key and Foreign Key relationship created by the Hierarchy Parser transformation.
2.3. Understanding the Primary Key & Foreign key relationship b/w the field segments in Hierarchy Parser

2.3.1 Root
As shown in image the Root segment contains the details of Mapping Name alone and a Primary key PK_Root that connects all other segments .
2.3.2 Annotations
Annotations contains the description of the mapping you entered during the development.
If you feel it is not necessary, this segment can be ignored.
But if is mandatory to have a proper description for every mapping in your working project and needs to be covered during the review process annotations will provide that metadata information.
Root and Annotations field segments are joined using the PK_Root and FK_Root.
2.3.3 Transformations
This is the most important segment which holds the important metadata information of all the transformations used in the mapping.
As you can see in the picture, transformations field segment is linked to several other field segments. We will discuss about couple of field segments which are important and linked to transformations.
The Root and Transformations field segments are joined using PK_Root and FK_Root.
2.3.4 Annotations1
Just like Annotations, the Annotations1 provide the description metadata of each of the transformation.
The Transformations and Annotations1 field segments are joined using PK_Transformations and FK_Transformations.
2.3.5 Advanced Properties
This is one other important field segment which holds a very important metadata information of the mapping transformations.
To list few of them are Lookup Sql Override, Lookup Source Filter, Pre SQL, Post SQL, Forward Rejected Rows and Tracing Level.
The Advanced properties segments contains only two fields name and value.
The Name field holds the property name like Tracing Level.
The Value field holds the value used for the property like Normal or Verbose etc.
The Transformations and AdvancedProperties segments are joined using PK_Transformations and FK_Transformations.
2.4. Aggregator transformation
If you are checking multiple metadata property values like we discussed here, it is going to create a separate record for each property. This results in duplication of same data in the final report we are generating.
This problem can be resolved using the Denormalizing technique.
So an aggregator transformation is used.
2.5. Look up transformation
In the Mapping JSON file which we are using as an input the associated Mapping Configuration task details are not embedded directly. Instead the MCT Id is available in the Mapping JSON file.
So a look up is performed on ContentsofExportPackage csv file to fetch the Mapping configuration task name of the mapping.
2.6. Target transformation
Target is flatfile which reads the information passed.
There will be ton of metadata fields that will be coming to the target. Make sure you only select the required fields in the Incoming fields section of the target so that the output will be clean.
3. Conclusion
The metadata information we are reading from JSON file is like a gold mine, the more you dig the more information you can get.
Don’t hesitate to experiment and read other field segments and see what metadata information they are providing.
Understand the primary key and foreign key relationship between the field segments.
Tip: If you are not finding the metadata information you are searching for, then it could be due to 2 reasons. Either you are not checking at the right place or you missed to define the metadata information in the Hierarchy Schema.
We have a complete 2 hour video course on Udemy explaining how you can build this from scratch. Along with a video guided course you will also get instructor support in case you need any help in building the tool at each and every step with a life time access.
The enrollment link to the course:
Informatica Cloud Data Integration – Automation Project



Hello Team, Could you please glance a bit on how can we migrate informatica Powercenter mapping into IICS.
Thanks in advance,
Normally you can import Powercenter mappings into IICS through Powercenter task using the exported XML but if you are asking about converting PC mappings into Data Integration mappings you can check about PC to Cloud Conversion Utility
https://network.informatica.com/onlinehelp/IICS/prod/P2C/en/index.htm#page/informatica-intelligent-cloud-services-pc-to-cloud-conversion/PC_to_Cloud_Conversion.html
Hi Team,
We got requirement build mappings (one to one) .Please suggest best way to build them by using automation processs.
You could try exploring the Informatica Cloud REST API resources to build a mapping task to get started.
Refer this article:
https://thinketl.com/how-to-create-mapping-task-in-iics-using-rest-api/