
1. Introduction
In our previous article we have discussed about Snowflake Streams using which we were able to identify the changes made in a RAW table and merge the changes into the target dimension table. But the process of verifying the Stream to see if any changes were done on raw table and merging them into target table is a manual process.
What if there is a process which execute the SQL statements on a schedule to merge the changes into the target table? Snowflake’s solution to this requirement is Snowflake Tasks.
In this article let us discuss more about Snowflake Tasks and Task-Trees and how to build them.
2. What is a Snowflake Task?
A Snowflake Task allows scheduled execution of SQL statements including calling a stored procedure or Procedural logic using Snowflake Scripting.
To create a task you need to be defining the following optional parameters using CREATE TASK along with the SQL code.
- The compute resources using which the SQL code executes using a WAREHOUSE parameter.
- The schedule details when the code needs to be executed using a SCHEDULE parameter.
Few key points to be noted before we get into building Snowflake Tasks
- Only one SQL statement is allowed to be executed through a task. If you need to execute multiple statements, build a procedure.
- Once task is created it will be in suspended state. You need to be manually resume the task using ALTER TASK.
- The Schedule parameter takes only minutes. It does not support second or hour.
- The minimum value of a schedule parameter is 1 minute and the maximum value that can be assigned to schedule parameter is 8 days i.e 11520 minutes.
3. Building a Snowflake Task
Tasks require compute resources to execute SQL code. Either of the following compute models can be chosen for individual tasks:
- User-managed (i.e. Virtual warehouse)
- Snowflake-managed (i.e. Serverless compute model)
3.1. Building User-managed Snowflake Task
You can manage the compute resources for individual tasks by specifying an existing virtual warehouse when creating the task. Make sure you choose a right sized warehouse for the SQL actions defined in task.
Below is an example which creates a user-managed task that inserts data into employees table every 5 minutes using COMPUTE_WH warehouse.
CREATE TASK mytask
WAREHOUSE = COMPUTE_WH
SCHEDULE = '5 MINUTE'
AS
INSERT INTO employees VALUES( EMPLOYEE_SEQUENCE.NEXTVAL,'F_NAME','L_NAME','101')
;If WAREHOUSE parameter is not defined, by default the task is created with Snowflake-managed compute resources, also referred as Serverless compute model.
3.2. Building Serverless Snowflake Task
The Serverless compute model for tasks enables you to rely on compute resources managed by Snowflake instead of user-managed virtual warehouses.
The compute resources are automatically scaled up or down by Snowflake as required for each workload in serverless model.
Below is the same example which creates a task using serverless compute model.
CREATE TASK mytask_serverless
USER_TASK_MANAGED_INITIAL_WAREHOUSE_SIZE = 'XSMALL'
SCHEDULE = '5 MINUTE'
AS
INSERT INTO employees VALUES( EMPLOYEE_SEQUENCE.NEXTVAL,'F_NAME','L_NAME','101')
;To specify the initial warehouse size for the task, set the USER_TASK_MANAGED_INITIAL_WAREHOUSE_SIZE parameter. Though the tasks starts with a XSMALL warehouse, if it sees a needs for more capacity, it will go for a bigger warehouse.
4. Scheduling a Snowflake Task
Snowflake Tasks are not event based, instead a task runs on a schedule. The Snowflake task engine has a CRON and NONCRON variant scheduling mechanisms. You must be familiar with CRON variant’s syntax if you are a Linux user.
A schedule must be defined for a task or the root task in a task tree; otherwise, the task only runs if manually executed using EXECUTE TASK.
4.1. Scheduling a Snowflake Task in NON-CRON notation
The above examples which we saw while building User-managed and Serverless tasks in sections 3.1 and 3.2 are scheduled in NON-CRON notation.

The disadvantage with NON-CRON notation is that you can only schedule a job which runs at a specific interval. You will not be able to schedule a job which triggers at a specified time.
For example if you scheduled a job to run every 10 minutes in NON-CRON mode and the job started at 12:07, the next run will be at 12:17.
4.2. Scheduling a Snowflake Task in CRON notation
To schedule a snowflake task in CRON notation, you must use the keyword USING CRON followed by 5 asterisks and the time zone.
Each asterisk denotes a specific time value as shown below.
| MIN | HOUR | DAY | MON | WEEKDAY | DESCRIPTION |
| * | * | * | * | * | Every minute |
| 0 | 2 | * | * | SUN | Every Sunday at 2 PM |
| 0 | 5,17 | * | 5 | * | Twice daily, at 5AM and 5PM in May month |
Below is an example of Snowflake task in CRON notation which runs every Sunday at 10 AM UTC.
CREATE OR REPLACE TASK my_crontask
WAREHOUSE = COMPUTE_WH
SCHEDULE = 'USING CRON * 10 * * SUN UTC'
AS
INSERT INTO employees VALUES( EMPLOYEE_SEQUENCE.NEXTVAL,'F_NAME','L_NAME','101')
;5. Turning the Snowflake Tasks on and off
Once task is created, its status can be verified in Snowflake using SHOW TASKS.
SHOW TASKS;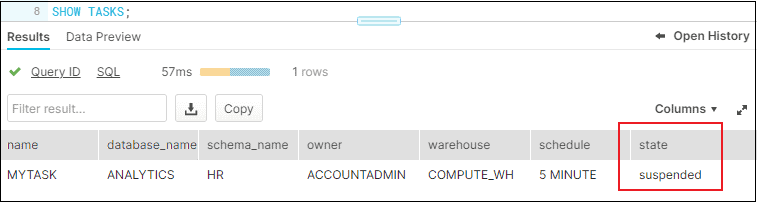
The initial status of the task will be “suspened” when created. To turn on a Snowflake task, issue below alter task command.
ALTER TASK mytask RESUME;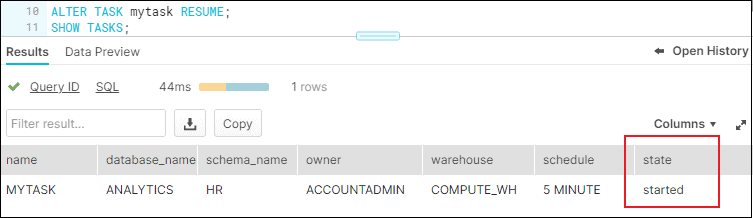
To turn off a Snowflake task, issue below alter task command.
ALTER TASK mytask SUSPEND;6. How to verify the task history of a Snowflake Task?
The status of every task run can be verified using the below query which provides the entire task history.
--CHECK TASK HISTORY
SELECT * FROM TABLE(INFORMATION_SCHEMA.TASK_HISTORY()) WHERE NAME = 'MYTASK';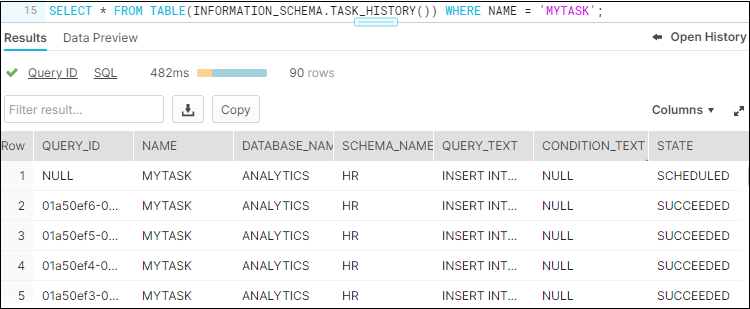
If there is a failure you can find the error_code and error_message associated with the failure.
7. What is Snowflake Task Tree?
Consider a scenario where you wanted to trigger another task immediately after an initial task completes and so on. This is supported in Snowflake by creating a B-Tree-like task structure which is referred as Task Tree.
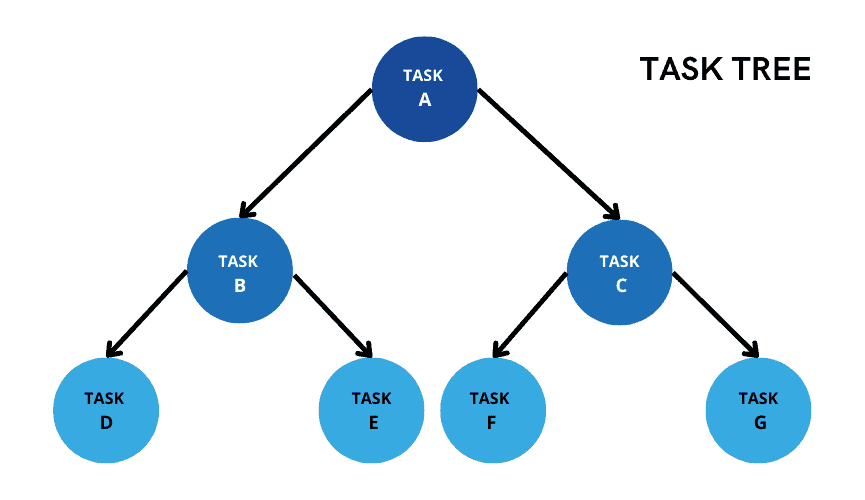
You can have only 1 root task and all child tasks are linked to the root task based on task dependency (i.e. before or after). Root tasks will have scheduler defined, and all child tasks follow sequential execution as per their dependency defined. The child tasks runs only after all specified predecessor task have successfully completed their own run.
The following example shows a task mytask set as a dependency for the task mytask_2 to trigger. The task mytask_2 which is a child task has no schedule of its own.
CREATE OR REPLACE TASK mytask_2
WAREHOUSE = COMPUTE_WH
AFTER mytask
AS
INSERT INTO mytable(ts) VALUES(CURRENT_TIMESTAMP)
;Make sure the root task is suspended before assigning a child task; otherwise the child task creation fails.
We can verify the task dependence by using the following query
--CHECK DEPENTANT TASKS
SELECT * FROM TABLE(INFORMATION_SCHEMA.TASK_DEPENDENTS(TASK_NAME => 'mytask', RECURSIVE => FALSE));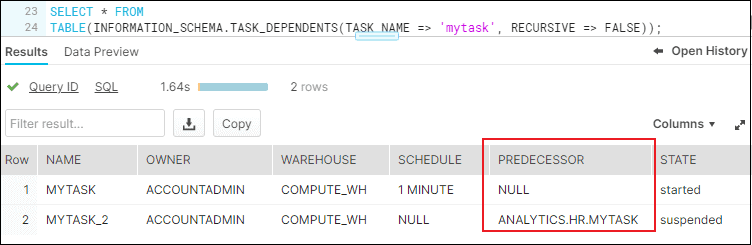
Consider a scenario where taskA is a root task and taskB and taskC are its child tasks. You wanted to define a taskD and specify taskB and taskC as its dependencies. This kind of task dependency set up is currently not supported in Snowflake where a task is dependent on multiple tasks.
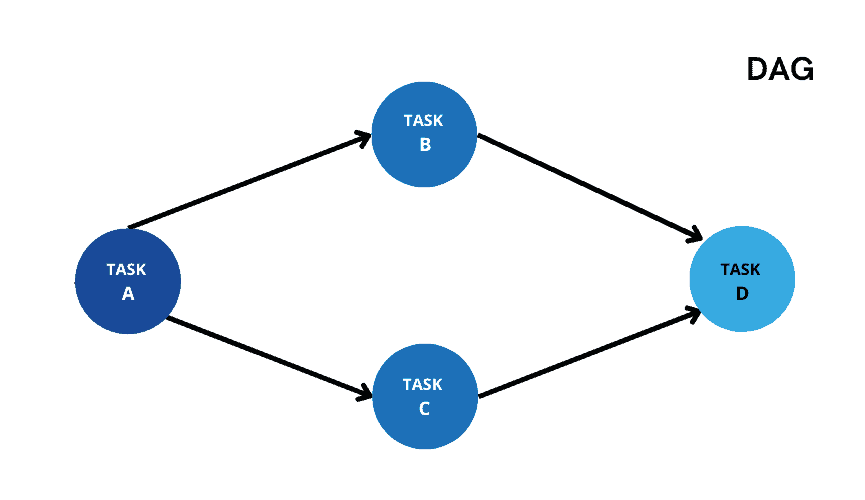
Directed Acyclic Graph (DAG) of tasks is currently available under public preview as of June 2022 where it is possible to set these kind of dependencies.
8. Building a Snowflake Task that tracks INSERT operations from a Stream
Tasks can be combined with table streams for continuous ELT workflows to process recently changed table rows.
The below task tracks data for INSERT operations from a stream and inserts changes into a table every 5 minutes. The task polls the stream using the SYSTEM$STREAM_HAS_DATA function to determine whether change data exists and, if the result is FALSE, skips the current run.
CREATE OR REPLACE TASK my_streamtask
WAREHOUSE = COMPUTE_WH
SCHEDULE = '5 minute'
WHEN
SYSTEM$STREAM_HAS_DATA('my_stream')
AS
INSERT INTO EMPLOYEE(id,name,salary) SELECT id,name,salary FROM my_stream WHERE metadata$action = 'INSERT' AND metadata$isupdate = 'FALSE';9. Building a Snowflake Task that calls a Stored Procedure
The following query creates a task named mytask_sp that calls a stored procedure MY_STORED_PROC every hour.
CREATE TASK mytask_sp
WAREHOUSE = MYWH
SCHEDULE = '60 MINUTE'
AS
CALL MY_STORED_PROC()
;10. Manually executing a Snowflake Task
The EXECUTE TASK command manually triggers a single run of a scheduled task independent of the schedule defined for the task. This SQL command is useful for testing new or modified tasks before you enable them to execute SQL code in production.
EXECUTE TASK mytask;In summary tasks are very handy in Snowflake, they can be combined with Streams, Snowpipe and other techniques to make them extremely powerful.
Subscribe to our Newsletter !!
Related Articles:

A step by step guide on automating continuous data loading into Snowflake through Snowpipe on Microsoft Azure.

There are three different types of views in Snowflake – Non-Materialized, Materialized and Secure Views.

Secure Data Sharing in Snowflake enables account-to-account sharing of selected database objects in your account with other.

