
Introduction
Salesforce is a cloud based integrated Customer Relationship Management(CRM) solution that gives organizations a single, shared view of every customer of all departments.
Informatica Intelligent Cloud Services (IICS) provides Salesforce connector to securely connect and perform actions on Salesforce objects.
Let us discuss in detail the common issues faced while processing data from Salesforce in Informatica Cloud and how to solve them and ways to improve the performance.
1. Fixing QUERY_TIMEOUT Issue
One of the most common issues faced while reading Salesforce data from Informatica Cloud is the QUERY_TIMEOUT issue. The error message in the session log would be as below
Fault code [QUERY_TIMEOUT]. Reason [Your query request was running for too long.].The above error occurs when the SOQL query generated by Informatica READER is unable to fetch the entire records from Salesforce. The READER waits for only couple of minutes to read the data using SOQL query before it fails.
Salesforce is not like other relational databases and is not very much optimized for querying. Salesforce uses its own version of SQL called SOQL which translates to Salesforce Object Query Language.
Follow below methods to resolve the QUERY TIMEOUT issues
1.1 Select only the required fields from the Salesforce Object
Salesforce objects usually contains larger number of fields. When you are directly reading the Salesforce object from Informatica, you might be unnecessarily reading all the fields in an object whereas you only need a handful of them.
While reading data from Salesforce through Informatica cloud, select only the fields you want to read. You can either do this by writing a Custom Query or deleting the unwanted fields from Fields section after selecting the source object.
This removes a lot of overhead on query and the READER might be able to read the required data in time.
1.2 Apply filters only on Indexed Fields
Salesforce standard fields which are common in every object are usually indexed. It makes the query easy to fetch the data from Salesforce by applying filters on indexed fields rather than from an unindexed field.
In case you need to filter on some custom fields which are not indexed and you are facing QUERY_TIMEOUT issues, check with Salesforce admin team to get the field Indexed.
1.3 Split the Query with multiple filters
Including too many filters in the source query also sometimes leads to QUERY TIMEOUT issues especially when you are using Like operator in the filter condition.
Consider this example.
SELECT Id, IsDeleted ,RecordTypeId ,LastName ,FirstName ,CreatedDate, LastModifiedDate ,Agency_Code__c ,External_Id__c FROM Account Where LastModifiedDate >= $LastRunTime and External_Id__c like '%Sales%'The above query is an Incremental load on Account object using $LastRunTime built-in Informatica system variable.
In the above query,
- I have selected only the required fields from Account Object.
- I have applied filter condition on LastModifiedDate which is a standard field and has standard index applied.
- Another filter condition is on External_Id__c field which is a custom field and has custom Index applied.
All looks good but in the real world scenario this query is giving me QUERY TIMEOUT error most of the times even when there are no records to be read in a particular incremental load.
But when I removed the filter on External_Id__c field and simply run the query as below, the job never failed.
SELECT Id, IsDeleted ,RecordTypeId ,LastName ,FirstName ,CreatedDate, LastModifiedDate ,Agency_Code__c ,External_Id__c FROM Account Where LastModifiedDate >= $LastRunTimeWhat is happening?
The Account object I am reading from Informatica Cloud has millions of records in it. In each incremental load I am only reading few thousands of records. As I already said Salesforce is not like regular relational databases and is clearly struggling to perform a Like operation on External_Id__c field even though we have passed another filter on LastModifiedDate field to filter the records.
How to add the Like condition in such scenarios?
If you only wanted to load the records which contains ‘Sales’ in the external_id__c field, removing the filter will not serve the purpose.
But instead of placing the filter on the source end, read the data from Account object with only incremental filter on LastModifiedDate and once the data is read from Salesforce, filter those records which do not contain ‘Sales’ in the External_Id__c field using Informatica transformations before loading into target.
Even though you will be reading more records each incremental load than required, it solves the QUERY TIMEOUT issue and the extra filter condition can be applied through Informatica transformations in the mappings.
Use trial and error method with the filters. Decide which filters to apply directly on source and which filters to be applied in mapping if you are facing QUERY TIMEOUT issue while using multiple filters on Salesforce object.
2. Choose proper fields to perform Incremental loading from Salesforce Objects
2.1 LastModifiedDate VS SystemModStamp
Both LastModifiedDate and SystemModStamp are system fields and are present in every Salesforce object.
LastModifiedDate is the date time when a record was last modified by a User.
SystemModStamp is the date and time when a record was last modified by a User or by an automated process such as a trigger. So even when there is no actual change in the data of the record, the SystemModStamp of the record might get updated.
Using SystemModStamp might result in fetching unnecessary records in an incremental load which is not expected.
Always use LastModifiedDate field from a Salesforce object to read Incremental data.
2.2 Incremental Data Loading using IICS System Variables
IICS provides access to following system variables which can be used as a data filter variable to filter newly inserted or updated records.
$LastRunTime returns the last time when the task ran successfully.
$LastRunDate returns only the last date on which the task ran successfully.
Both Salesforce and Informatica Cloud stores the datetime values of LastModifiedDate and $LastRunTime in Greenwich Mean Time (GMT) respectively.
This makes a perfect and easy combination between Informatica Cloud and Salesforce to perform Incremental loading as both values are stored in same time zone.
The filter condition can be mentioned as simple as below to perform Incremental loading of Salesforce data from Informatica Cloud.
LastModifiedDate > $LastRunTime3. Create a local database copy of Salesforce object to perform Lookup
If you are trying to look up on a Salesforce object using a Lookup transformation in Informatica Cloud, there are certain limitations.
- Informatica Cloud do not support creating an Unconnected lookup on a Salesforce object.
- Informatica Cloud do not support using SQL override query with Salesforce objects.
- Informatica Cloud uses one API call per a lookup on Salesforce object which is expensive and slows the process down.
Hence it is not recommended to lookup directly on Salesforce object. Instead create a local database table as a copy of Salesforce object with only required fields.
This table should be incrementally updated after completion of each incremental load into Salesforce. This helps in using complete features of a Lookup transformation on Salesforce data and also helps in joining the Salesforce data with the staging data in your database directly.
4. Enable PK Chunking while reading large number of records from Salesforce
PK Chunking is an advanced option that can be configured for Salesforce Bulk API tasks in a Source transformation.
If PK Chunking is enabled, then Salesforce internally generates separate batches based on the PK Chunking size given. Each batch is a small chuck of a bulk query created based on the Primary Key(ID) of the queried records.
It is recommended to use PK Chunking when you need to read a large number of records from Salesforce. Usually when you need to do an initial load or a Full load reading millions of records from Salesforce, enabling PK Chunking gives huge performance boost.
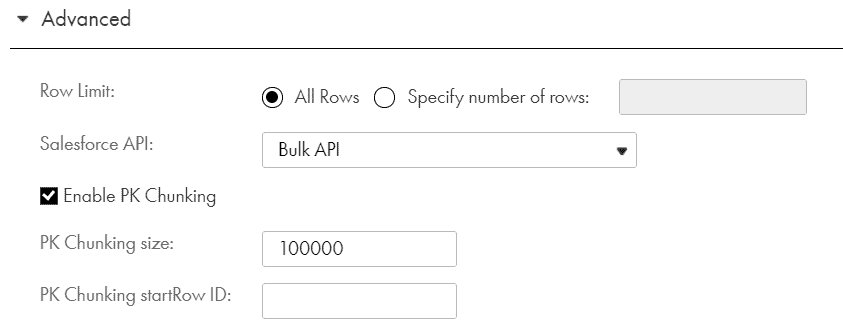
If your incremental load deals with only few thousands of records, do not use PK Chunking or enable Bulk API mode as it actually slows down the process. Use Standard API mode to read records from Salesforce when the expected records from Salesforce is less in your incremental loads.
5. Enable Bulk load while loading records into Salesforce
While configuring a Salesforce object in a target transformation there are two options available which defines which API method to be used to process records while loading data into Salesforce.
The two option available are Standard API and Bulk API. By default, the agent uses the Salesforce Standard API.
The advantages of using Bulk API method to load records into Salesforce is
- You can enable a Bulk API job for monitoring by selecting the Monitor Bulk option in target Advanced properties tab.
- With monitoring enabled, the Data Integration service requests the status of each batch from the Salesforce and logs them in the session log.
- This also helps in generation of SFDC error file with rejected records and SFDC success file with success records.
- Bulk API method by default process the records in parallel batches. Use default parallel load to increase performance when you are not concerned about the target load order.
- Use a serial load when you want to preserve the target load order by selecting Enable Serial Mode in target Advanced properties tab.
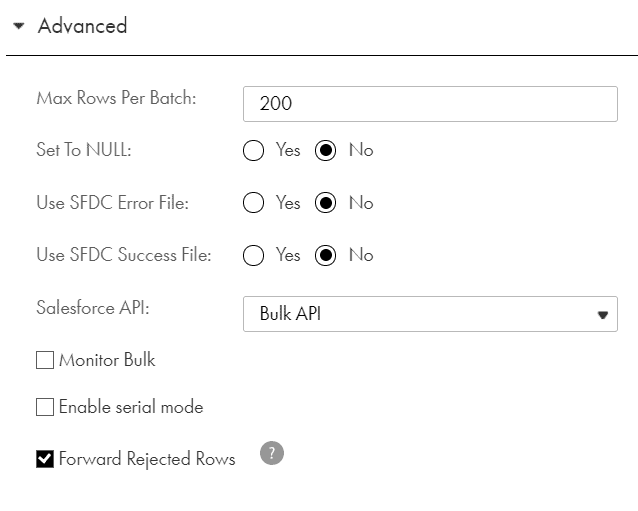
There is no limitation with using Bulk API method with incremental loads. This can also be enabled with the regular incremental loads where the number of records processed into Salesforce is less.
6. Fixing Informatica Cloud Metadata Issues
Sometimes I have faced some strange issues with the metadata refresh of Informatica Cloud.
This usually occurs when a new task or an updated task (with changes in the already existing task) is migrated into another environment.
For example, I have a task which loads data into a Case object in Salesforce and is currently running fine in Production environment. Now I have added logic to update an another field in existing mapping and migrated the updated task to Production.
The job runs fine but the new field do not get loaded in Salesforce. But from Informatica end there won’t be any errors or warnings and completes without any issues.
Usually this kind of issues are related to Informatica cloud metadata refresh. This issue can be usually resolved by reimporting the task again into Informatica Cloud.
It might seem strange but I have faced this issue particularly with Salesforce Connections. So it is important to complete that first load and monitor it after the code deployment. If there are such issues with a new field not getting loaded where rest of the fields are loaded, reimport the task.
7. Enable Debug Mode in Salesforce to debug Informatica failures
One of the common failures we get while reading data from Salesforce is Query failed.
This usually occurs when the SOQL query fired by Informatica is not accepted by Salesforce. The most common reason would be a field missing in Salesforce object and you are trying to query the same field. Since the field you are trying to query is not present, the job fails.
If the issue is due to a field missing, you will find the details of the field which is missing in the session log and the issue could be resolved by either creating the field in Salesforce or dropping the field from Informatica Cloud.
But sometimes the same Query failed issue occurs due to permission issues with User with which you are connecting to Salesforce. In such cases there won’t be any details in the session log which mentions the actual cause of the issue.
In such cases, check with the Salesforce support team to enable the Debug Mode on the object in Salesforce which is throwing error while reading from Informatica Cloud and retrigger the job.
Enabling Debug mode adds more detailed output for some warnings and errors and helps Salesforce team to resolve the issue.
I personally faced such issues and the Salesforce team was able to identify after enabling the Debug Mode that certain permissions on the object for Informatica Integration User were removed as part of an internal release which is not allowing the Informatica Integration User to read the object.
8. Avoid duplicates in Incremental loads by scheduling jobs at proper timings
This a known issue from Informatica Cloud which results in picking the record’s data which got modified during the Informatica task run.
We have a mapping which reads data from Salesforce Case object modified between yesterday’s 3AM to current day’s 3AM. The Informatica job is scheduled to trigger at 04:30 AM and usually completes by 04:35 AM.
In one particular case there is a record which got modified at 1:30 AM and later again modified at 04:32 AM by a user.
In the ideal scenario, in the current day’s run, the LastModifiedDate of the record should be picked as 01:30 AM. The same record should be picked in next day’s run with LastModifiedDate as 04:32 AM.
In actual scenario the record got picked in the current day’s run because the record is modified between the yesterday’s and current day’s 03:00 AM timeframe. But while the job is still reading the data, the record again got modified and LastModifedDate updated to 04:32 AM in Salesforce.
As a result, instead of picking the LastModifedDate as 01:30 AM, the value was read as 04:32 AM in the current day’s run. Since the record satisfies the filter condition of next day’s run, the record is again read from salesforce with LastModifiedDate as 04:32 AM.
This resulted in duplicates as same record is read with same LastModifiedDate twice.
The issue arose as the record got modified while the Informatica job is still running and the Informatica reader picked the updated value instead of the value which was present before the job got started.
We later scheduled the job at 05:00 AM which is the closing time of business and no updates are expected after 05:00 AM.
If you are expecting the updates to be happening to the data you are reading during the Informatica job scheduled period, it might result in duplicates in your incremental data. Make sure you schedule the jobs during which no modifications are expected on particular set of data you are reading.
9. Conclusion
All the issues discussed here are something which I have come across in my experience and all the possible solution to resolve them are discussed here.
There are certain things which I did not discuss here like updating Null values into Salesforce. Also employ your own ETL error handling mechanism to avoid rejections from Salesforce for fields which are of Pick List type or mandatory fields in Salesforce.
Let me know if you have encountered any other specific issues while working with Salesforce.



When using the Bulk API in Salesforce target properties, why are we not able to parameterize the Error Dir, Error File in the advanced session properties of Mapping Task. This is possible when using the Standard API. Any specific reason for this?
Hi Hal,
This is strange. Make sure ‘Use SFDC Error File’ and ‘Monitor Bulk’ options are enabled when Bulk API mode is selected.
We have a scenario, where we have to lookup on a salesforce table based on a key field and a field which matches partially. In this case we have to use like operator. Can anyone guide me how we can use Like operator in Cloud Data Integration.Any suggestions are appreciated.
First lookup based on Key field and extract all the matching records. Next in expression transformation check if the field returned partially matches with your input using INSTR function.
Let me know if this helps. If you have found any other work around, please do let us know.