
1. Introduction
Snowpark is a developer framework from Snowflake that allows developers to interact with Snowflake directly and build complex data pipelines using Python. In our previous articles, we discussed what Snowpark is and how to set up a Python development environment for Snowpark and write data into Snowflake using Snowpark.
In this article, we will explore how to copy data from CSV files into Snowflake tables using Snowpark.
2. Steps to COPY Data from CSV Files INTO Snowflake table using Snowpark
Follow the below steps to copy data from CSV files into the Snowflake table using Snowpark.
STEP-1: Establish a Connection with Snowflake from Snowpark
To establish a connection with the Snowflake database from Snowpark, make use of the Session class in Snowpark which establishes a connection with a Snowflake database and provides methods for creating DataFrames and accessing objects.
When you create a Session object, you provide connection parameters to establish a connection with a Snowflake database as shown below.
import snowflake.snowpark as snowpark
from snowflake.snowpark import Session
connection_parameters = {
"account": "snowflake account",
"user": "snowflake username",
"password": "snowflake password",
"role": "snowflake role", # optional
"warehouse": "snowflake warehouse", # optional
"database": "snowflake database", # optional
"schema": "snowflake schema" # optional
}
session = Session.builder.configs(connection_parameters).create()STEP-2: Define a schema parameter of StructType containing names and data types of columns.
StructType is a data type representing a collection of fields that may have different data types. It is commonly used to define the schema of a DataFrame or a column with a nested structure.
Define a schema parameter as a StructType that includes the names and corresponding data types of the columns in the CSV files from which data should be copied as shown below.
from snowflake.snowpark.types import IntegerType, StringType, StructField, StructType, DateType
schema = StructType(
[StructField("EMPLOYEE_ID", IntegerType()),
StructField("FIRST_NAME", StringType()),
StructField("LAST_NAME", StringType()),
StructField("EMAIL", StringType()),
StructField("HIRE_DATE", DateType()),
StructField("SALARY", IntegerType())
])STEP-3: Read Data from Staged Files into a Snowpark DataFrame using Session.read Method
DataFrameReader class in Snowpark provides methods for reading data from a Snowflake stage to a DataFrame with file format-specific options. A DataFrameReader object can be created through Session.read method as shown below.
#// Use the DataFrameReader (session.read) to read from a CSV file
df_employee = session.read.schema(schema).options({"field_delimiter": ",", "skip_header": 1}).csv('@my_s3_stage/Inbox/employee.csv')
In the above code,
- The file format-specific properties are passed using the options() method.
- The schema of the file defined as a StructType parameter is passed using the schema() method.
- The file path and stage details are passed by calling the method corresponding to the CSV format, csv().
The following is the data read by the DataFrame from the stage file employee.csv
df_employee.show(5)
----------------------------------------------------------------------------------
|"EMPLOYEE_ID" |"FIRST_NAME" |"LAST_NAME" |"EMAIL" |"HIRE_DATE" |"SALARY" |
----------------------------------------------------------------------------------
|100 |Steven |King |SKING |2003-06-17 |24000 |
|101 |Neena |Kochhar |NKOCHHAR |2005-09-21 |17000 |
|102 |Lex |De Haan |LDEHAAN |2001-01-13 |17000 |
|103 |Alexander |Hunold |AHUNOLD |2006-01-03 |9000 |
|104 |Bruce |Ernst |BERNST |2007-05-21 |6000 |
----------------------------------------------------------------------------------STEP-4: COPY Data from Snowpark DataFrame INTO Snowflake table using DataFrame.copy_into_table Method
DataFrame.copy_into_table method in Snowpark executes a COPY INTO <table> command to load data from files in a stage location into a specified table.
This method is slightly different from the COPY INTO command. It automatically creates a table if it doesn’t exist and the input files are CSV, unlike the COPY INTO <table> command.
Syntax:
The following is the syntax to copy data from a CSV file into a table using the DataFrame.copy_into_table method in Snowpark.
DataFrame.copy_into_table(table_name, [optional_parameters])Example:
The following code copies the data from DataFrame df_employee into the EMPLOYEE table in Snowflake.
#// writing data using DataFrame.copy_into_table method
copied_into_result = df_employee.copy_into_table("employee")When executed, this code is translated and executed as SQL in Snowflake through the Snowpark API. The resulting SQL statement is as follows:
-- Verifying if table exists
show tables like 'employee'
-- Creating table
CREATE TABLE employee(
"EMPLOYEE_ID" INT,
"FIRST_NAME" STRING,
"LAST_NAME" STRING,
"EMAIL" STRING,
"HIRE_DATE" DATE,
"SALARY" INT)
-- Copying data from Stage file into Snowflake table
COPY INTO employee FROM @my_s3_stage/Inbox/employee.csv
FILE_FORMAT = ( TYPE = CSV FIELD_DELIMITER = ',' SKIP_HEADER = 1 )The following code confirms that the table is created and displays the count of records loaded into the EMPLOYEE table.
session.table("employee").count()
------
| 107|
------3. How to Reload CSV data into Snowflake Table from Snowpark?
The COPY INTO <table> command in Snowflake do not process the files which are already processed and have not changed.
To reload (duplicate) data from a set of staged data files that have not changed, add FORCE=TRUE in the DataFrame.copy_into_table Method as shown below.
#// Reloading data using DataFrame.copy_into_table method
copied_into_result = df_employee.copy_into_table("employee", force=True)The following code confirms that data is reloaded into the EMPLOYEE table showing that the record count is doubled.
session.table("employee").count()
------
| 214|
------4. How to Skip Error Records when copying data into Snowflake Table from Snowpark?
The ON_ERROR clause specifies what to do when the COPY command encounters errors in the files. The default behavior aborts the load operation unless a different ON_ERROR option is explicitly set in the COPY statement.
Syntax:
DataFrame.copy_into_table(table_name, on_error="<copy_options>")The following are all the supported values of ON_ERROR copy option
CONTINUE
- Continue to load the file if errors are found.
SKIP_FILE
- Skip a file when an error is found.
SKIP_FILE_num (ex: SKIP_FILE_10)
- Skip a file when the number of error rows found in the file is equal to or exceeds the specified number.
SKIP_FILE_num%’ (ex: ‘SKIP_FILE_10%’)
- Skip a file when the percentage of error rows found in the file exceeds the specified percentage.
ABORT_STATEMENT
- Abort the load operation if any error is found in a data file.
The following code Skips Error Records if any, when copying data into Snowflake from a Snowpark DataFrame
#// Specifying the COPY option to continue on error
copied_into_result = df_employee.copy_into_table("employee", force=True, on_error="CONTINUE")5. How to Specify File Names to Load Data into Snowflake Table from Snowpark?
Consider we are reading all the files in a stage location using a DataFrame in Snowpark. Using the files parameter in the DataFrame.copy_into_table method, we can explicitly specify the list of files from which data should be copied into a Snowflake table.
Syntax:
DataFrame.copy_into_table(table_name, files=['file1.csv', 'file2.csv'])The following code copies data only from the employee.csv file in the stage location into the EMPLOYEE table in Snowflake.
#// Reads all files from the Inbox folder in Stage location
df_employee = session.read.schema(schema).options({"field_delimiter": ",", "skip_header": 1}).csv('@my_s3_stage/Inbox/')
#// Copies data from only specified files from stage location
copied_into_result = df_employee.copy_into_table("employee", files=['employee.csv'], force=True)6. How to Specify File Pattern to Load Data into Snowflake Table from Snowpark?
Using the pattern parameter in the DataFrame.copy_into_table method, we can explicitly define the file pattern from which data should be copied into a Snowflake table.
Syntax:
DataFrame.copy_into_table(table_name, pattern='<regex_file_pattern>')The following code copies data from stage files that match the file pattern specified in the DataFrame.copy_into_table method into the Snowflake EMPLOYEE table.
#// Reads all files from the Inbox folder in Stage location
df_employee = session.read.schema(schema).options({"field_delimiter": ",", "skip_header": 1}).csv('@my_s3_stage/Inbox/')
#// Copies data from files which match the specified file pattern from stage location
copied_into_result = df_employee.copy_into_table("employee", pattern='emp[a-z]+.csv', force=True)7. How to COPY INTO Snowflake Table with Different Structure from Snowpark?
When the structure of columns is different between the stage files and the Snowflake table, we can specify the order of target columns to which data should be saved in the table using the target_columns parameter in the DataFrame.copy_into_table method.
Syntax:
DataFrame.copy_into_table(table_name, target_columns=['<column_1>','<column_2>',..])The following is the order of columns in the Stage file vs Snowflake table vs target_columns parameter
| employee.csv | EMPLOYEE | target_columns parameter |
| EMPLOYEE_ID | ID | ID |
| FIRST_NAME | FNAME | FNAME |
| LAST_NAME | LNAME | LNAME |
| SALARY | EMAIL_ADDRESS | |
| HIRE_DATE | EMAIL_ADDRESS | JOIN_DATE |
| SALARY | JOIN_DATE | SALARY |
The following code copies data from the DataFrame into the EMPLOYEES table where the order of columns is different between the stage file and the Snowflake table using the target_columns parameter.
#// copying data into the table with a different structure than file
copied_into_result = df_employee.copy_into_table("employees", \
target_columns=['ID','FNAME','LNAME','EMAIL_ADDRESS','JOIN_DATE','SALARY'],\
force=True, on_error="CONTINUE")The following is the data loaded into the EMPLOYEES table in Snowflake.
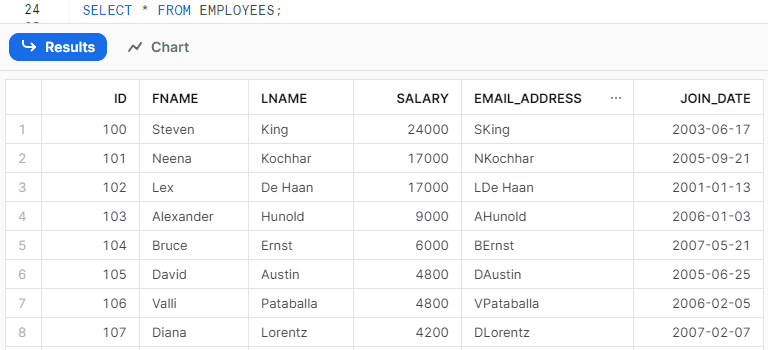
8. How to Transform CSV Data before Loading it into Snowflake table from Snowpark?
The data from CSV files can be transformed before loading into the Snowflake table using the transformations parameter in the DataFrame.copy_into_table method.
Syntax:
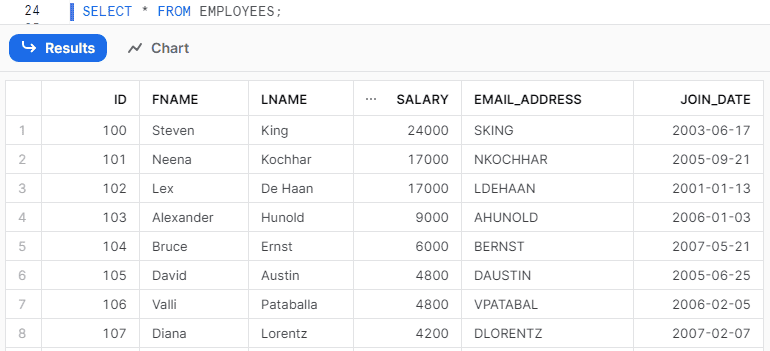
DataFrame.copy_into_table(table_name, transformations=[<transformed_columns>])The following code transforms the data in DataFrame before copying it into the EMPLOYEES table using the transformations parameter.
- The CSV file columns are represented as $1, $2, $3, and so on.
- For FNAME and LNAME table fields, we are copying the data of columns 2 and 3 from files by trimming the spaces using ltrim and rtrim functions.
- For the EMAIL_ADDRESS field of the table, we are concatenating the first letter of column 2 with column 3 data using concat and substr functions.
#// Transform data and load to snowflake
from snowflake.snowpark.functions import ltrim, rtrim, concat, substr
copied_into_result = df_employee.copy_into_table("employees", \
target_columns=['ID','FNAME','LNAME','EMAIL_ADDRESS','JOIN_DATE','SALARY'], \
transformations=['$1', ltrim(rtrim('$2')), ltrim(rtrim('$3')), concat(substr('$2',1,1),'$3'), '$5', '$6'], \
force=True, on_error="CONTINUE")To find the complete list of supported functions in the transformations parameter, refer to Snowflake Documentation.
The following is the transformed data loaded into the EMPLOYEES table in Snowflake.
Subscribe to our Newsletter !!
Related Articles:
- Introduction to Snowflake Snowpark for Python
- HOW TO: Create and Read Data from Snowflake Snowpark DataFrames?
- HOW TO: Write data into Snowflake from a Snowpark DataFrame?
- HOW TO: COPY Data from CSV Files INTO Snowflake Table using Snowpark?
- HOW TO: Add a New Column to a Snowpark DataFrame?
- HOW TO: Drop a Column from a Snowpark DataFrame?
- HOW TO: Remove Duplicates in a Snowflake Snowpark DataFrame?
- HOW TO: Update a DataFrame in Snowflake Snowpark?
- HOW TO: Delete Rows From a DataFrame in Snowflake Snowpark?
- HOW TO: Merge two DataFrames in Snowflake Snowpark?
- HOW TO: Execute SQL Statements in Snowflake Snowpark?
- Aggregate Functions in Snowflake Snowpark
- GROUP BY in Snowflake Snowpark
- Joins in Snowflake Snowpark
- IN Operator in Snowflake Snowpark
- Window Functions in Snowflake Snowpark
- CASE Statement in Snowflake Snowpark
- UDFs in Snowflake Snowpark


