
1. How to connect Salesforce from Informatica Cloud?
In order to access data from Salesforce, a connection needs to be created initially from Administrator’s tab.
The connection information created can then be used in Data Integration tasks either to retrieve data or process data into the Salesforce.
The requirements to connect to a Salesforce environment are
- User Name – User name for the Salesforce account.
- Password – Password for the Salesforce account.
- Security Token – Security token generated from the Salesforce application.
- Service URL – URL of the Salesforce service. The service URL is based on the Salesforce version.

2. When does a Security Token not required to create a Salesforce connection?
- In order to avoid using Security Token while setting up a Salesforce connection, Informatica Cloud IP ranges should be entered in the Trusted IP Ranges in the Salesforce Application.
- The Informatica Cloud Trusted IP ranges can be found by hovering over the question mark symbol available next to Security Token option in a Salesforce connection.
3. What is PK Chunking?
- PK Chunking is an advanced option that can be configured for Salesforce Bulk API tasks in a Source transformation.
- If PK Chunking is enabled, then Salesforce internally generates separate batches based on the PK Chunking size given. Each batch is a small chuck of a bulk query created based on the Primary Key(ID) of the queried records.
- It is recommended to enable PK chunking for objects with more than 10 million records. This improves performance.
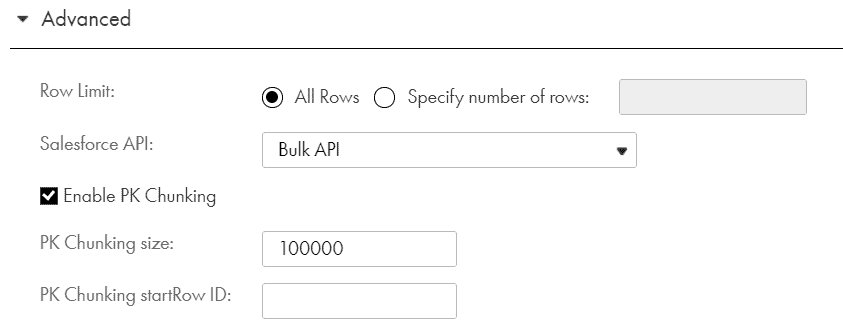
- For example, let’s say you enable PK chunking Account table with 10,000,000 records. Assuming a chunk size of 250,000 the query is split into 40 small queries. Each query is submitted as a separate batch.
4. How to add a filter condition in a source transformation when the source is a Salesforce object?
- When the source is a salesforce object, defining the filter condition under the Filter option available under Query Options won’t work. The Filter condition needs to be defined under SOQL Filter Condition available under Advanced tab of source transformation.

- The Filter option under Query Options tab can be used only if the filter condition needs to be parameterized.
- Alternatively, the Source Type can be selected as Query and the filter condition can be passed in the source query defined.
5. How does a Boolean field from Salesforce object is processed in Informatica Cloud?
- The Boolean fields from Salesforce are read as Integer fields when read from Informatica cloud tasks. The Salesforce field values TRUE and FALSE are read as ’1’ and ‘0’ by Informatica respectively.
- In order to insert/update the Boolean fields in salesforce object, define an integer field of value ‘1’ or ‘0’ and the value in salesforce will be updated with either TRUE or FALSE accordingly.
6. What is difference between Salesforce Bulk API and Standard API?
- Salesforce Standard API processes up to 200 records in one API call. However, Bulk API processes about 10,000 records in one API call.
- If the Salesforce object contains large data sets, then it is advisable to use Bulk API. The performance of the task on would be much faster when loading large data sets using Bulk API when compared to the same job run on Standard API.
Similarly, it is advisable to use Standard API when dealing with smaller data sets and the performance would be much faster compared to Bulk API. - Standard API makes Synchronous calls in which the thread will wait until it completes its tasks before proceeding to next. In a Synchronous call, the code runs in single thread.
Bulk API makes Asynchronous calls in which the thread will not wait until it completes its tasks before proceeding to next. In an Asynchronous call, the code runs in multiple threads which helps to do many tasks as background jobs.
7. Can Salesforce objects be used in IICS Lookup transformation?
- Salesforce objects can be used in a connected Lookup transformation to look up data. But the Informatica Cloud do not support using Salesforce objects in Unconnected Lookup transformation.
8. What is the difference between Soft delete and Hard delete of Salesforce records? How to enable them from Informatica Cloud?
- When you delete records from Salesforce object, they are moved to Recycle Bin and these records are said to be soft deleted. The soft deleted records can be restored.
- When you delete records permanently from Salesforce object, they are said to be hard deleted. The hard deleted records cannot be restored.
- To enable hard delete of salesforce records from IICS, check the Hard Delete option when you select the Delete operation in Target transformation. If the option is not selected, the delete operation is considered as soft delete.

9. How to Include archived and deleted rows in the source data queried from Informatica Cloud?
- When Salesforce objects are used as a source, by default the archived and deleted records in the salesforce object are omitted from search query. To include the archived and deleted records in search query enable the Include archived and deleted rows in the Source option available under Query Options of a source transformation.

10. What is the default timezone in which date fields are stored in Salesforce objects?
- In Salesforce by default the DateTime fields store the time information in UTC timezone and display the appropriate date and time to the user based on the user’s personal timezone settings.
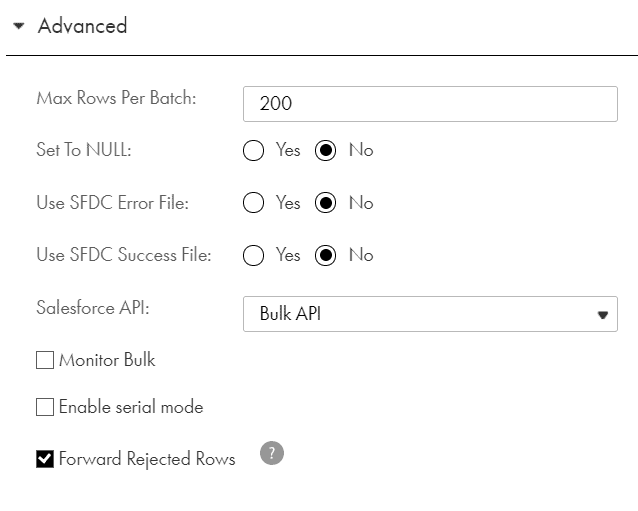
11. What are the advanced properties available for a Salesforce target?
Max Batch Size
- Maximum number of records the agent writes to a Salesforce target in one batch. Default is 200 records.
- This property is not used in Bulk API target sessions.
Set Fields to Null
- Replaces values in the target with null values from the source.
- By default, the agent does not replace values in a record with null values during an update or upsert operation.
Use SFDC Error File
- Generates the error log files for a Bulk API target session. By default, the agent does not generate the error log files.
- To generate an error log file for a Bulk API target session, select the Monitor Bulk option.
Use SFDC Success File
- Generates the success log files. By default, the agent does not generate the success log files.
- To generate a success log file for a Bulk API target session, select the Monitor Bulk option.
Salesforce API
- Defines which API method to be used to process records while loading data into Salesforce. The two option available are Standard API and Bulk API.
- By default, the agent uses the Salesforce Standard API.

12. What are the advanced properties available for a Salesforce target with Bulk load?
Monitor Bulk:
- You can enable a Bulk API task for monitoring. With monitoring enabled, the Data Integration service requests the status of each batch from the Salesforce and logs them in the session log.
- By default, the Data Integration service does not monitor Bulk API jobs. Without monitoring, the activity log and session log contains information about batch creation, but does not contain details about batch processing or accurate job statistics.
Enable Serial Mode
- The Salesforce service can perform a parallel or serial load for a Bulk API task. By default, it performs a parallel load.
- In a parallel load, the Salesforce service writes batches to target at the same time. In a serial load, the Salesforce service writes batches to targets in the order it receives them.
- Use a parallel load to increase performance when you are not concerned about the target load order. Use a serial load when you want to preserve the target load order.
Test your Understanding
IICS Interview Questions Quiz
Five Multiple Choice Questions


