
1. Introduction
In modern data pipelines, it’s common for raw files to be delivered into cloud storage locations. Identifying the structure of this data before loading it into Snowflake tables can be challenging and is usually a manual process.
Snowflake simplifies this process with its INFER_SCHEMA function, which eliminates the need for manual schema discovery and makes it easier to create tables or external tables directly from raw data.
In this article, let us explore how to use INFER_SCHEMA in Snowflake.
2. Understanding INFER_SCHEMA in Snowflake
The INFER_SCHEMA function automatically scans the staged files, detects their metadata schema, and retrieves the corresponding column definitions. This function supports Parquet, Avro, ORC, JSON, and CSV files.
Syntax:
INFER_SCHEMA(
LOCATION => '{ internalStage | externalStage }'
, FILE_FORMAT => '<file_format_name>'
-- optional
, FILES => ( '<file_name>' [ , '<file_name>' ] [ , ... ] ) -- List of one or more files
, IGNORE_CASE => TRUE | FALSE -- Column names detected to be treated case sensitive
, MAX_FILE_COUNT => <num> -- Max number of files to be scanned from stage
, MAX_RECORDS_PER_FILE => <num> --Max number of records to be scanned per file
, KIND => '{ STANDARD | ICEBERG }' -- Kind of file metadata schema to be scanned from stage
)3. Deriving Table Structure with INFER_SCHEMA
Consider we have raw files in the external location, which can be accessed from Snowflake using the external stage my_s3_stage.
-- List files in External stage location
list @my_s3_stage/Inbox;
Create a File Format defined for the files you wish to read from the stage location.
-- Create a file format that sets the file type as CSV
CREATE OR REPLACE FILE FORMAT my_csv_format
TYPE = csv
PARSE_HEADER = true;Note that the PARSE_HEADER option must be set to TRUE for CSV files to determine column names using the first row as a header.
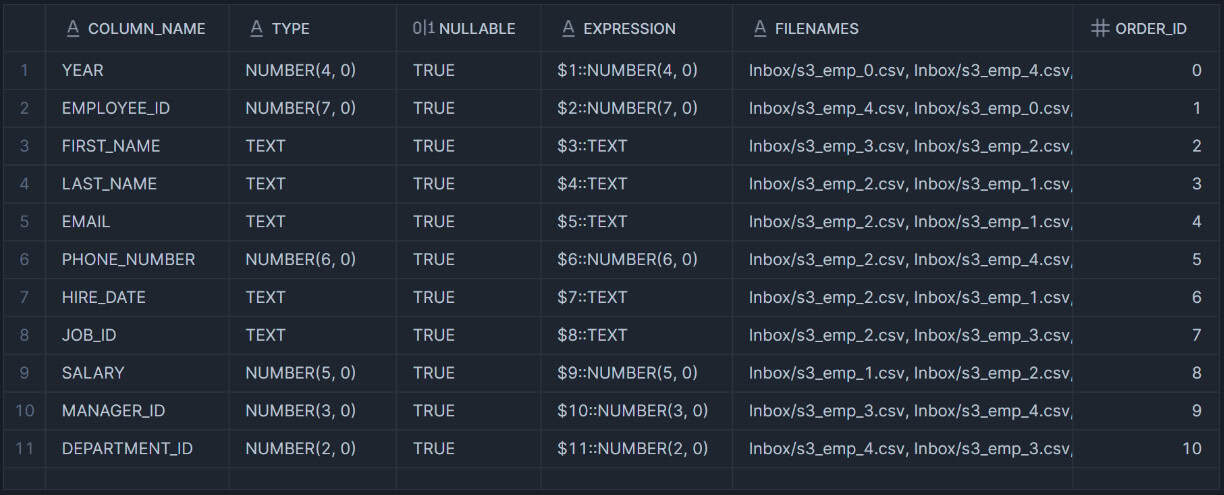
The following query retrieves the Snowflake column definitions for CSV files in the stage location using the INFER_SCHEMA function.
-- Query the INFER_SCHEMA function
SELECT * FROM TABLE(
INFER_SCHEMA(
LOCATION=>'@my_s3_stage/Inbox/',
FILE_FORMAT=>'my_csv_format'
)
);Output:
4. Creating and Loading Tables Using INFER_SCHEMA
Snowflake tables can be created using the schema detected by INFER_SCHEMA from the staged files using CREATE TABLE … USING TEMPLATE syntax.
The following query creates a table named employees using the detected schema from the staged CSV files.
- The USING TEMPLATE clause dynamically generates a table definition from the schema returned by INFER_SCHEMA.
- Instead of manually specifying each column and data type, Snowflake automatically builds the table structure based on the inferred metadata, which is provided in the form of an array.
-- Create table with USING TEMPLATE using INFER_SCHEMA
CREATE OR REPLACE TABLE employees
USING TEMPLATE (
SELECT ARRAY_AGG(OBJECT_CONSTRUCT(*)) WITHIN GROUP (ORDER BY order_id)
FROM TABLE
(
INFER_SCHEMA(
LOCATION=>'@my_s3_stage/Inbox/',
FILE_FORMAT=>'my_csv_format'
)
)
)
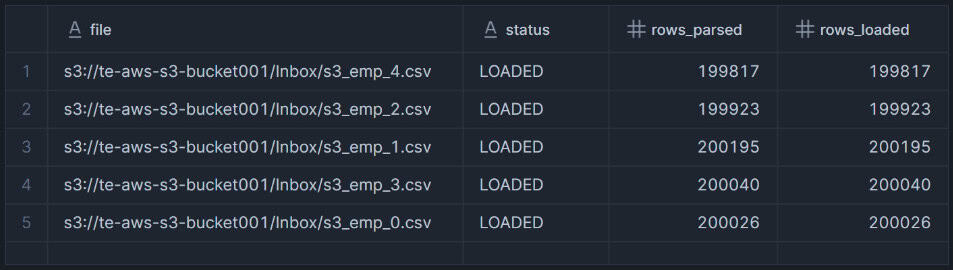
;Once the table is created, data can be loaded using the COPY INTO statement as shown below.
-- Load the CSV data using MATCH_BY_COLUMN_NAME
COPY INTO employees FROM @my_s3_stage/Inbox/
FILE_FORMAT = (
FORMAT_NAME= 'my_csv_format'
)
MATCH_BY_COLUMN_NAME=CASE_INSENSITIVE
;
Note that if you are using a file format with PARSE_HEADER=TRUE, it is mandatory to use the MATCH_BY_COLUMN_NAME clause. This ensures that columns in the staged files are matched to the target table columns by name rather than by position.
5. Creating External Tables with INFER_SCHEMA
Snowflake External tables can be created using the schema detected by INFER_SCHEMA from the staged files using CREATE EXTERNAL TABLE … USING TEMPLATE syntax.
5.1. Creating External Tables on CSV Files
External tables don’t support the PARSE_HEADER option. Therefore, if you create an external table on CSV files using INFER_SCHEMA, the columns will be named C1, C2, C3, and so on, based on their position.
Step 1: Define a File Format
Create a file format for reading the CSV files. To ignore the first record, which is a header row, set SKIP_HEADER = 1 in the file format.
-- Create a file format that sets the file type as CSV
CREATE OR REPLACE FILE FORMAT csv_format
TYPE = csv
SKIP_HEADER = 1;
;Step 2: Create the External Table
The following query creates an external table named ext_employees using the detected schema from staged CSV files. Snowflake will assign default column names (C1, C2, …), and the data types are automatically inferred.
-- Create External table with USING TEMPLATE using INFER_SCHEMA
CREATE OR REPLACE EXTERNAL TABLE ext_employees
USING TEMPLATE (
SELECT ARRAY_AGG(OBJECT_CONSTRUCT(*)) WITHIN GROUP (ORDER BY order_id)
FROM TABLE
(
INFER_SCHEMA(
LOCATION=>'@my_s3_stage/Inbox/',
FILE_FORMAT=>'csv_format'
)
)
)
LOCATION=@my_s3_stage/Inbox/
FILE_FORMAT=csv_format
;Step 3: Rename Column Names Manually
Since external tables created on CSV files use default column names (C1, C2, …), you can manually rename the columns to more meaningful names.
5.2. Creating External Tables on Parquet Files
Creating external tables on Parquet files is more straightforward than on CSV files, since the table is automatically created with the actual column names inferred by INFER_SCHEMA, eliminating the need for manual renaming.
-- Create a file format that sets the file type as Parquet
CREATE OR REPLACE FILE FORMAT my_parquet_format
TYPE = PARQUET
;
-- Create external table with USING TEMPLATE using INFER_SCHEMA
CREATE OR REPLACE EXTERNAL TABLE ext_pqt_employees
USING TEMPLATE (
SELECT ARRAY_AGG(OBJECT_CONSTRUCT(*)) WITHIN GROUP (ORDER BY order_id)
FROM TABLE(
INFER_SCHEMA(
LOCATION=>'@my_s3_stage/parquet',
FILE_FORMAT=>'my_parquet_format'
)
)
)
LOCATION=@my_s3_stage/parquet
FILE_FORMAT=my_parquet_format
; 6. Summary
The INFER_SCHEMA function in Snowflake helps eliminate manual effort in identifying table structures from raw files stored in cloud stages.
- Combined with the USING TEMPLATE clause, it allows you to directly create table or external table definitions from inferred schemas without manually specifying columns and data types.
- When working with CSV files, keep in mind that external tables don’t support headers, so column renaming may be needed.
- For formats like Parquet, Snowflake automatically picks up the column names, making the process much simpler.
Overall, INFER_SCHEMA together with USING TEMPLATE provides a fast and reliable way to build tables from staged files.
Subscribe to our Newsletter !!
Related Articles:
- Snowflake Micro-partitions & Data Clustering
- Snowflake File Formats
- Types of Snowflake Tables
- Types of Views in Snowflake
- Types of Snowflake Stages: Data Loading and Unloading Features
- HOW TO: Create External Stages in Snowflake
- HOW TO: Create Snowflake External Tables?
- HOW TO: Load and Query JSON data in Snowflake?
- INSERT and Multi-Table Inserts in Snowflake
- HOW TO: Create Snowflake Iceberg Tables?
- Creating Snowflake Iceberg tables using AWS Glue as Catalog
- Data Load using COPY INTO Command in Snowflake
- Data Unloading using COPY INTO Command in Snowflake
- Snowflake Directory Tables: Query and Manage Staged Files
- Snowflake File URLs: Securely Access and Share Staged Files


