
Snowflake Data Cloud is a cloud based data analytic platform delivered as a fully managed SaaS (software as a service) offering. Snowflake enables data storage, processing, and analytic solutions that are faster, easier to use, and far more flexible than traditional offerings.
Snowflake is completely built from the ground up for the cloud with a unique multi-cluster shared data architecture that delivers the performance, scale, elasticity, and concurrency today’s organizations require.
Before we get into understanding the architecture of Snowflake, let us discuss about Shared-Disk and Shared Nothing architectures
Used in traditional databases, Shared-Disk architecture is an architecture in which the cluster nodes share same storage device but each node has its own own CPU and Memory. Any machine can read or write any portion of data into central data storage. Scalability and performance are limitations.
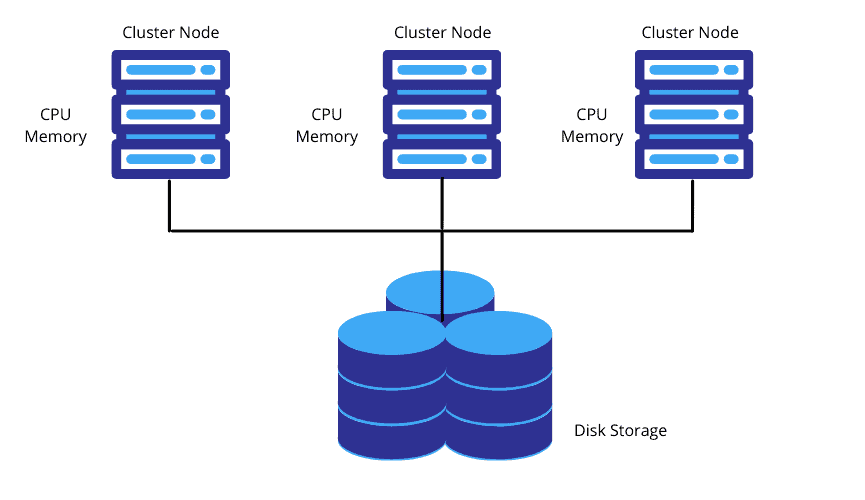
One storage layer accessible by all cluster nodes.
Contrary to Shared-Disk architecture, Shared-Nothing architecture has distributed cluster nodes with their own CPU, Memory along with Disk storage. In this architecture the data is partitioned and stored across these compute nodes locally as each node has its own disk storage. This model might lead to data loss if the copies of partitioned data is not maintained as backup in another cluster nodes, as there is no redundancy.
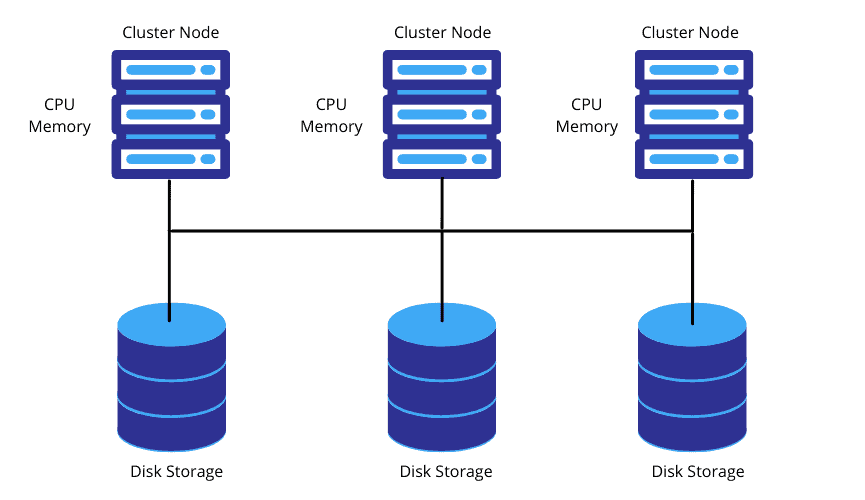
Each node in the cluster stores a portion of the entire data set locally which enables Massive Parallel Processing.
Snowflake Architecture
Snowflake’s architecture is a hybrid of traditional Shared-Disk and Shared-Nothing database architectures. It brings best of the two worlds in which it uses a central data repository accessible from all compute nodes and processes queries using MPP (massively parallel processing) compute clusters where each node in the cluster work on parts of a computational task in parallel.
With the hybrid Shared Data model, Snowflake has the data management simplicity of a Shared-Disk architecture with the performance benefits of a Shared-Nothing architecture.
Snowflake’s unique architecture consists of three key layers:
- Database Storage
- Query Processing
- Cloud Services
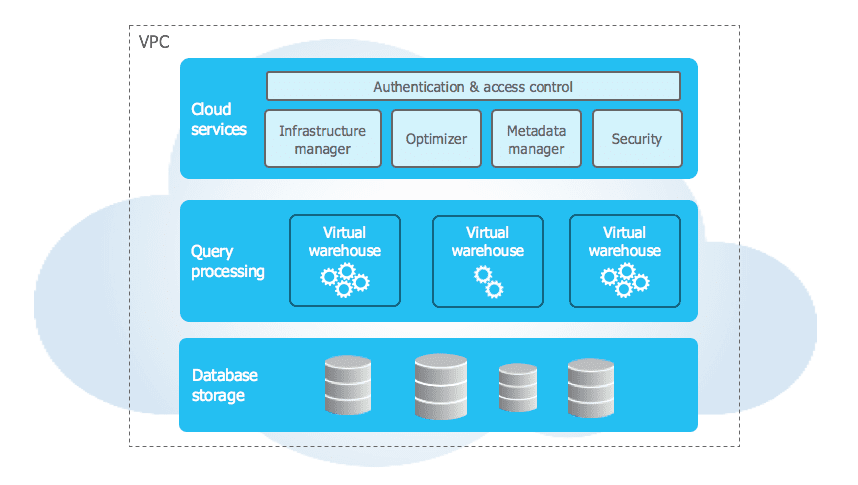
Database Storage
Snowflake uses highly secure cloud storage to maintain all your data. Snowflake stores all data in databases. A database is a logical grouping of objects consisting primarily of tables and views organized into one or more schemas.
Snowflake supports both structured data using standard SQL data types and semi-structured non-relational data like JSON, Parquet, Avro etc. through Variant data type. Regardless of type of data Snowflake supports querying data through ANSI Standard SQL.
As data is loaded into tables, snowflake converts it into an optimized columnar compressed format and encrypts it using AES-256 strong encryption. Data objects in Snowflake are only accessible via SQL queries through the Compute layer and are hidden to users.
Query Processing
Query execution is performed in the compute layer which is the ‘Muscle’ of the system. A compute layer is where queries are executed using resources provisioned from a cloud provider. Unlike traditional architectures snowflake allows you to create multiple independent compute clusters called Virtual Warehouses that all access the same data storage layer without contention or performance degradation.
Each virtual warehouse is an independent compute cluster made up of multiple compute nodes that does not share compute resources with other virtual warehouses. As a result, each virtual warehouse has no impact on the performance of other virtual warehouses.
Advantages of Virtual Warehouses
Below are the some of the advantages of Snowflake Virtual Warehouses
- A Virtual Warehouse can be scaled up or down at any time without any downtime or disruption.
- When a virtual warehouse is resized, all subsequent queries take advantage of the additional resources.
- Virtual Warehouses can also be set to auto-suspend or auto-resume so that warehouses are suspended after a specific period of inactive time and resumed when a query is submitted.
- Since virtual warehouses access the same data storage layer, any updates or inserts become immediately available to all other warehouses.
- They support concurrency without resource contention so that separate virtual warehouses can be used to handle loading and querying concurrently.
Cloud Services
The Snowflake Cloud Services layer is the ‘Brain’ of the system which coordinates and manages the entire system. These services tie together all of the different components of Snowflake in order to process user requests, from login to query dispatch.
The services layer is fully maintained by snowflake and runs on compute instances provisioned by Snowflake from the cloud provider.
Services layer is responsible for
- Authentication of users.
- Manages sessions, secures data and performs query compilation and optimization.
- Infrastructure Management by managing virtual warehouses and storage.
- Coordinating data storage updates and access control so that the same version of the data is available to all warehouses with no impact on availability or performance.
- A key component of the services layer is the Metadata Store of tables and micro partitions which powers a number of unique snowflake features including zero copy cloning, time travel and data sharing.
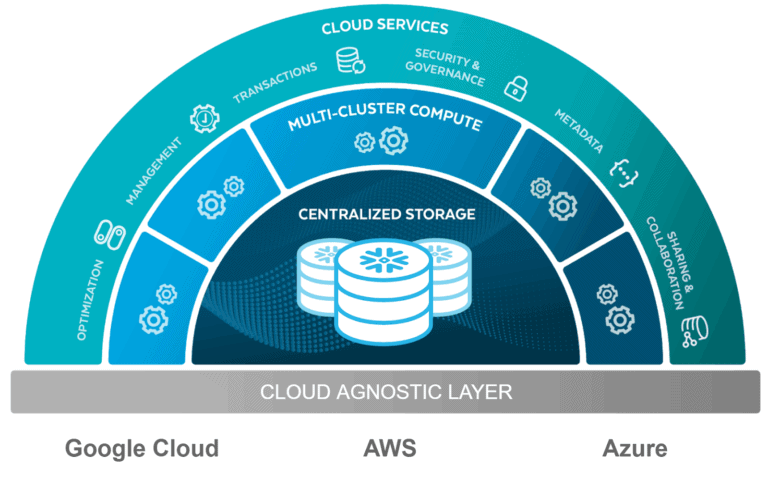
Cloud Agnostic Layer
Unlike many cloud data warehouses, Snowflake doesn’t run on its own cloud. It uses the storage and compute resources from popular cloud computing platforms – Amazon Web Services (AWS), Microsoft Azure and Google Cloud Platform (GCP). Snowflake cannot run on a private cloud infrastructure, either on-premises or hosted.
With Snowflake, you interact only with the Service layer. The Service layer interacts with Compute and Storage layers, which in turn interact with the underlying cloud infrastructure provider.
Test your understanding
Subscribe to our Newsletter !!
Related Articles:




