
Chapter-2: Introducing a dummy field
Introduction
Let us discuss in detail in what scenarios we have to introduce a dummy field in transformations and how it helps.
Consider the following as the source data
| EMP_ID | EMP_NAME | SALARY |
| 101 | Michael | 1000 |
| 102 | Ronald | 2000 |
| 103 | Christoph | 2000 |
| 104 | Jennifer | 2500 |
| 105 | John | 1500 |
Q1. Design a mapping to calculate the average salary of employees
Expected Output:
| AVG_SALARY |
| 1800 |
Solution:
- Map the output from source to an Aggregator transformation.
- In the aggregator transformation, create a new field AVG_Salary of type Integer and assign value as AVG(salary) in the aggregator.
- Do not specify Group By on any field in aggregator.
- Map the output from Aggregator to a Target transformation and select AVG_Salary as the incoming field.

Q2. Design a mapping to display the average salary amount of all the employees against each employee record.
Description:
Calculate the average salary of employees and display all the employee records along with average salary in the department as a new field for each record.
Expected Output:
| EMP_ID | EMP_NAME | SALARY | AVG_SALARY |
| 101 | Michael | 1000 | 1800 |
| 102 | Ronald | 2000 | 1800 |
| 103 | Christoph | 2000 | 1800 |
| 104 | Jennifer | 2500 | 1800 |
| 105 | John | 1500 | 1800 |
Solution:
- Map the output from source to an Expression transformation.
- In the expression, create a field “EXP_Dummy” and assign value as 1.
- Map the output from expression to an aggregator transformation.
- In the aggregator transformation, create two new fields as shown below.
AVG_SALARY = AVG(salary)
AGG_Dummy = 1 - Do not specify Group By on any field in aggregator.
- Pass the output of expression and aggregator transformation to a Joiner transformation and join on the DUMMY fields.
EXP_Dummy = AGG_Dummy - In the joiner transformation check the sorted input property, then only you can connect both expression and aggregator to joiner transformation. Make sure the data coming from source is sorted. Else sort the data using Sorter after the source transformation.
- Map the output from Joiner to the Target transformation
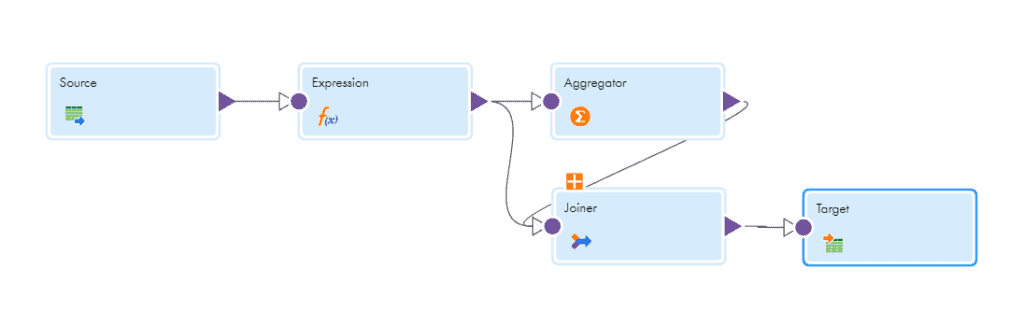
The Aggregator gives a single aggregated output which is average salary 1800 in this case. But in order to load the average salary value for each source record, a common value is needed to join the aggregator output and expression output. This is where the DUMMY field we introduced comes into picture.
Q3. Design a mapping to find employees whose salary is more than the average salary of employees.
Description:
Compare the salary of each employee with the average salary amount and if the salary is amount is greater than the average salary amount, then display the record.
Expected Output:
| EMP_ID | EMP_NAME | SALARY | AVG_SALARY |
| 102 | Ronald | 2000 | 1800 |
| 103 | Christoph | 2000 | 1800 |
| 104 | Jennifer | 2500 | 1800 |
Solution:
- The solution is exactly same until the Joiner transformation like we discussed in previous scenario.
- Map the output from Joiner to a Filter transformation.
- In Filter transformation specify the Advanced Filter Condition as
SALARY > AVG_SALARY - Map the output from Filter to a Target transformation.
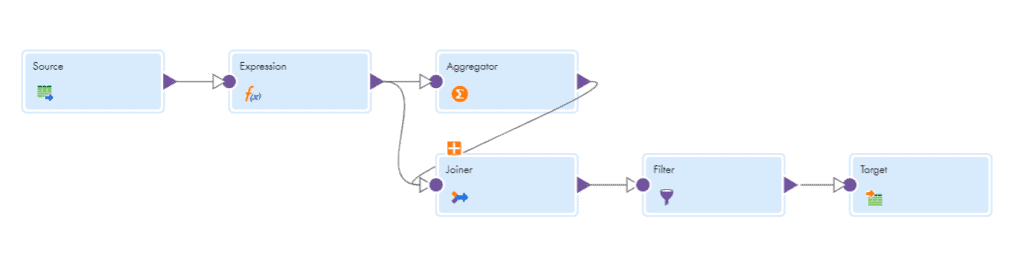
NOTE: If the Department ID is provided in source data and asked to calculate the same scenarios as we discussed here “department wise”, the data should be Grouped By Department_ID in aggregator. The output from expression and aggregator should also be joined based on Department_ID . Since there is no common element in the scenarios we discussed, we have introduced DUMMY field.
We have discussed on how to write a SQL query for similar scenario in the SQL Analytic Functions article.
Q4. Design a mapping to load only first two source records into the target.
Description:
Add sequence numbers to each record and filter the first two records from source to load into target.
Expected Output:
| EMP_ID | EMP_NAME | SALARY |
| 101 | Michael | 1000 |
| 102 | Ronald | 2000 |
Solution:
- Map the output from source to an Expression transformation.
- In expression, create a new variable field V_count of type integer and assign value as V_count+1
- Create a new output field O_count of type integer and assign value as V_count.
- In expression the fields created will be as below
V_count = V_count+1
O_count = V_count - Map the output from expression to a filter transformation.
- In the filter transformation provide the filter condition as O_count <3
- Map the output from the filter to a target transformation.

Q5. Design a mapping to load only last two source records into the target.
Description:
Identify the last two records from source data and load into target.
Expected Output:
| EMP_ID | EMP_NAME | SALARY |
| 104 | Jennifer | 2500 |
| 105 | John | 1500 |
Solution:
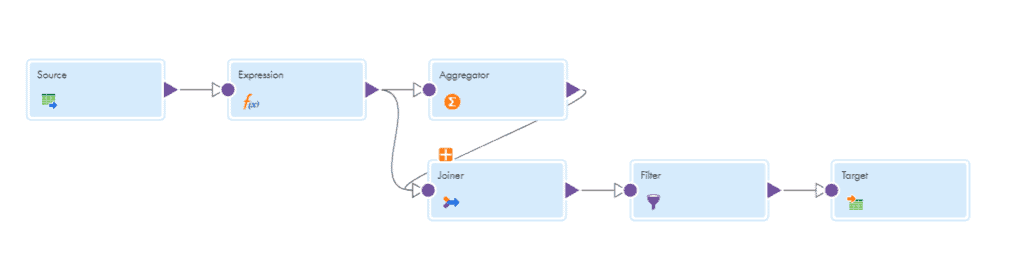
- Map the output from source to an Expression transformation.
- In expression create an additional output field EXP_Dummy and assign value as 1 along with V_count and O_count fields as discussed in above scenario.
- In expression the fields created will be as below
V_count = V_count+1
O_count = V_count
EXP_Dummy = 1 - Map the output from expression to an aggregator transformation.
- In the aggregator transformation, create two new output fields as shown below.
Record_Count = Count(EMP_ID)
AGG_Dummy = 1 - Do not specify Group By on any field in aggregator.
- Pass the output of expression and aggregator transformation to a Joiner transformation and join on the DUMMY fields.
EXP_Dummy = AGG_Dummy - In the joiner transformation check the property sorted input, then only you can connect both expression and aggregator to joiner transformation.
- The Joiner output will be as below
| EMP_ID | EMP_NAME | SALARY | O_Count | Record_Count |
| 101 | Michael | 1000 | 1 | 5 |
| 102 | Ronald | 2000 | 2 | 5 |
| 103 | Christoph | 2000 | 3 | 5 |
| 104 | Jennifer | 2500 | 4 | 5 |
| 105 | John | 1500 | 5 | 5 |
10. Map the output from joiner to a filter transformation.
11. In the filter transformation specify the Advanced Filter Condition as Record_Count-O_count<2
12. Map the output from the filter to a target transformation.
Consider the following as the source data
| Col |
| a |
| b |
| c |
Q6. Design a mapping to load the output of the cross join of the source table on itself
Description:
A cross join produces the Cartesian product of the tables involved in the join. The size of a Cartesian product result set is the number of rows in the first table multiplied by the number of rows in the second table. In this example it is 3×3
Expected Output:
| Col_A | Col_B |
| a | a |
| a | b |
| a | c |
| b | a |
| b | b |
| b | c |
| c | a |
| c | b |
| c | c |
Solution:
- Map the output from source to two different expression transformations.
- In both the expression transformation create an output field “Dummy” and assign the value as 1.
- Pass the output of both the expression transformations to a Joiner transformation and join on the DUMMY fields.
Dummy=Dummy - In the joiner transformation check the sorted input property, then only you can connect both the expression outputs.
- Map the output from filter to target transformation.

Conclusion
I hope by now it is clear when to introduce a dummy field.
When there is no common field between two tables to join, introduce a dummy field in both tables and join them based on that dummy field. Be it joining an aggregated value to the source data or self-join of a table this method can be used.


