
dropDuplicates() Method in Snowflake Snowpark
The dropDuplicates() method in Snowpark returns a new DataFrame with all duplicate rows removed. This method removes all rows that have identical values across all columns. It also allows you to remove duplicates based on a subset of columns in the DataFrame.
Below are the two possible approaches to remove the duplicate rows using the dropDuplicates() method.
1. Removing Duplicates across all columns
Consider the following DataFrame as a source for the demonstration of removing duplicates in Snowpark.
data = [[1,1,1],
[1,1,1],
[1,1,0],
[1,0,0],
[1,0,0],
[0,0,0]]
df = session.createDataFrame(data, schema=["a","b","c"])
df.show()
-------------------
|"A" |"B" |"C" |
-------------------
|1 |1 |1 |
|1 |1 |1 |
|1 |1 |0 |
|1 |0 |0 |
|1 |0 |0 |
|0 |0 |0 |
-------------------The following code demonstrates removing duplicate rows from a DataFrame using the dropDuplicates() method.
df_unique = df.dropDuplicates()
df_unique.show()
-------------------
|"A" |"B" |"C" |
-------------------
|1 |1 |1 |
|1 |1 |0 |
|1 |0 |0 |
|0 |0 |0 |
-------------------The duplicate rows (1,1,1) and (1,0,0) are removed in the new DataFrame created using the dropDuplicates() method.
2. Removing Duplicates Based on a Subset of columns
The following code demonstrates removing duplicate rows based on a subset of columns from the DataFrame using the dropDuplicates() method.
#// Removing Duplicates Based on a Column "A" //
df_unique = df.dropDuplicates("a")
df_unique.show()
-------------------
|"A" |"B" |"C" |
-------------------
|0 |0 |0 |
|1 |1 |1 |
-------------------In the above example, duplicates are removed based on column ‘A’, where the unique values are 1 and 0 (highlighted in red in the image below). Based on these two values, two unique records (highlighted in blue in the image below) are returned as output.
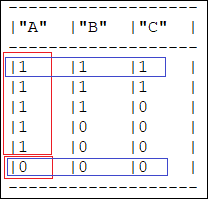
Below is another example where duplicates are removed from a Snowpark DataFrame based on columns “A” and “B”.
# Removing Duplicates Based on a Column "A" and "B"
df_unique = df.dropDuplicates("a","b")
df_unique.show()
-------------------
|"A" |"B" |"C" |
-------------------
|0 |0 |0 |
|1 |0 |0 |
|1 |1 |1 |
-------------------dropDuplicates() vs distinct() in Snowflake Snowpark
The `dropDuplicates()` method in Snowpark behaves exactly like the `distinct()` method when no subset of columns is specified for removing duplicates.
The following example demonstrates that the output of the `dropDuplicates()` and `distinct()` methods is identical.
df.show()
-------------------
|"A" |"B" |"C" |
-------------------
|1 |1 |1 |
|1 |1 |1 |
|1 |1 |0 |
|1 |0 |0 |
|1 |0 |0 |
|0 |0 |0 |
-------------------
df.dropDuplicates().show()
-------------------
|"A" |"B" |"C" |
-------------------
|1 |1 |1 |
|1 |1 |0 |
|1 |0 |0 |
|0 |0 |0 |
-------------------
df.distinct().show()
-------------------
|"A" |"B" |"C" |
-------------------
|1 |1 |1 |
|1 |1 |0 |
|1 |0 |0 |
|0 |0 |0 |
-------------------In both cases, the DataFrame is translated and executed as SQL using the “GROUP BY” clause in Snowflake by the Snowpark API, as shown below.
SELECT "A", "B", "C"
FROM(
SELECT
$1 AS "A",
$2 AS "B",
$3 AS "C"
FROM
VALUES
(1::INT, 1::INT, 1::INT),
(1::INT, 1::INT, 1::INT),
(1::INT, 1::INT, 0::INT),
(1::INT, 0::INT, 0::INT),
(1::INT, 0::INT, 0::INT),
(0::INT, 0::INT, 0::INT)
)
GROUP BY "A", "B", "C"
;When a subset of columns is specified in the `dropDuplicates()` method, the DataFrame is translated and executed as SQL using the “ROW_NUMBER” analytical function in Snowflake by the Snowpark API, as shown below.
df.dropDuplicates("a").show()
-------------------
|"A" |"B" |"C" |
-------------------
|0 |0 |0 |
|1 |1 |1 |
-------------------SELECT "A", "B", "C"
FROM
(
SELECT "A", "B", "C",
row_number() OVER (PARTITION BY "A" ORDER BY "A" ASC NULLS FIRST) AS "TXT3PTQCE5"
FROM
(
SELECT
$1 AS "A",
$2 AS "B",
$3 AS "C"
FROM
VALUES
(1::INT, 1::INT, 1::INT),
(1::INT, 1::INT, 1::INT),
(1::INT, 1::INT, 0::INT),
(1::INT, 0::INT, 0::INT),
(1::INT, 0::INT, 0::INT),
(0::INT, 0::INT, 0::INT)
)
)
WHERE
("TXT3PTQCE5" = 1::INT)
;Subscribe to our Newsletter !!
Related Articles:
- Introduction to Snowflake Snowpark for Python
- HOW TO: Create and Read Data from Snowflake Snowpark DataFrames?
- HOW TO: Write data into Snowflake from a Snowpark DataFrame?
- HOW TO: COPY Data from CSV Files INTO Snowflake Table using Snowpark?
- HOW TO: Add a New Column to a Snowpark DataFrame?
- HOW TO: Drop a Column from a Snowpark DataFrame?
- HOW TO: Remove Duplicates in a Snowflake Snowpark DataFrame?
- HOW TO: Update a DataFrame in Snowflake Snowpark?
- HOW TO: Delete Rows From a DataFrame in Snowflake Snowpark?
- HOW TO: Merge two DataFrames in Snowflake Snowpark?
- HOW TO: Execute SQL Statements in Snowflake Snowpark?
- Aggregate Functions in Snowflake Snowpark
- GROUP BY in Snowflake Snowpark
- Joins in Snowflake Snowpark
- IN Operator in Snowflake Snowpark
- Window Functions in Snowflake Snowpark
- CASE Statement in Snowflake Snowpark
- UDFs in Snowflake Snowpark


