
1. Introduction
While processing flat files using Flat File connection in Informatica Cloud, there is an option (Add Currently Processed Filename field) to add an additional filed in the source transformation which populates the name of the file from which the data is processed into target. This is extremely helpful when processing multiple files of same structure through Indirect File Loading method. This helps in reconciliation of record count between source and target systems.
When the same flat files are read from an Amazon S3 directory, the indirect method of loading files is still possible using Manifest files but the option to add the filename field is not yet supported using Amazon S3 v2 connection in Informatica Cloud.
In this article, we will explore a work around method which lets you add the filename filed while processing flat files from Amazon S3.
2. Problem Statement
We have a set of flat files of same structure and properties in an Amazon S3 folder.
The data from these flat files must be processed in a single session into a target table using Indirect file loading method in IICS.
As part of this process, it is essential to capture the information of filename from which each of the record is processed in a dedicated field within the target table.
3. Solution
Follow below steps to capture the information of filename from which the records are processed from flat files in an Amazon S3 folder.
1. Using AWS S3 CLI commands, sync the flat files in S3 directory to your local directory.
2. Create a dynamic file list which holds the list of all the flat files copied from the S3 to local directory.
3. Create a mapping with Flat File Source Connection and pass the dynamic file list as source with Source Type as File List.
4. Under the Fields section of the source transformation, check the Add Currently Processed Filename field option to populate filename field for each record.
5. Once the load is completed, remove the files copied from S3 to your local directory.
4. Demonstration of Solution
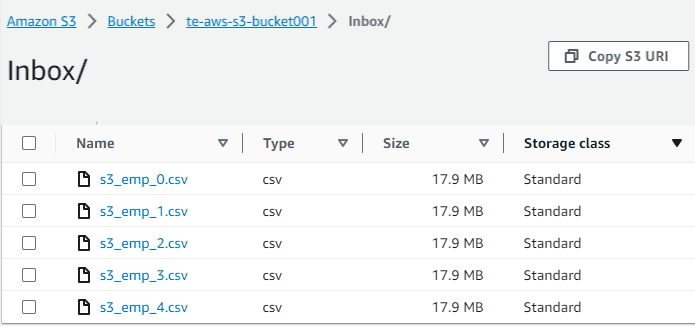
Below are the source S3 files from which the data needs to be processed into a target with filename information for each record.
4.1. Copy files from S3 to Local Directory
As a first step, copy the files from S3 directory to our local directory.
Below command recursively copies files from source S3 directory to destination local directory.
aws s3 sync <S3_DIR> <LOCAL_DIR>Below command recursively copies files of a defined pattern from source S3 directory to destination local directory.
aws s3 sync <S3_DIR> <LOCAL_DIR> --exclude "*" --include "<FILE_PATTERN>"4.2. Create a Dynamic File List
Once the files are copied from s3 to local directory, create a list file which holds the list of all files copied from s3 to local directory.
Below command creates a file which holds the list of all the files copied from s3 to local directory.
-- Windows:
dir /S /B "<LOCAL_DIR>\<FILE_PATTERN>" > "<LOCAL_DIR>\<LIST_FILE>"
-- Linux:
find <LOCAL_DIR> -name "<FILE_PATTERN>" > <LOCAL_DIR>/<LIST_FILE>4.3. Build a Script to automate file copy and list file creation
Since the above discussed activities needs to be executed before we run the actual mapping, lets automate these activities by building a script.
Below is the batch script supported on Windows which copies the files from s3 to local directory and create a dynamic file list.
@echo off
rem Set variables # Replace the values of variables as per your requirement
set S3_BUCKET=s3://te-aws-s3-bucket001/Inbox/
set LOCAL_DIR=C:\Infa
set FILE_PATTERN=s3_emp_*.csv
set LIST_FILE=s3_file_list.csv
rem Sync files from S3 to the local directory
aws s3 sync %S3_BUCKET% %LOCAL_DIR% --exclude "*" --include "%FILE_PATTERN%"
rem List the synced CSV files and save the list to a file
dir /S /B "%LOCAL_DIR%\%FILE_PATTERN%" > "%LOCAL_DIR%\%LIST_FILE%"Below is the shell script supported on Linux which copies the files from s3 to local directory and create a dynamic file list.
#!/bin/bash
# Set variables # Replace the values of variables as per your requirement
S3_BUCKET=s3://te-aws-s3-bucket001/Inbox/
LOCAL_DIR=Informatica/Scripts
FILE_PATTERN=s3_emp_*.csv
LIST_FILE=s3_file_list.csv
# Sync files from S3 to the local directory
aws s3 sync "$S3_BUCKET" "$LOCAL_DIR" --exclude "*" --include "$FILE_PATTERN"
# List the synced CSV files and save the list to a file
find "$LOCAL_DIR" -type f -name "$FILE_PATTERN" > "$LOCAL_DIR/$LIST_FILE"4.4. Build a Mapping to read the file list and perform Indirect File Loading
In our previous article, we have discussed in detail what Indirect File Loading is how to configure the same in Informatica Cloud.
Follow below steps to process all the file copied from s3 to local directory using Indirect File Loading method.
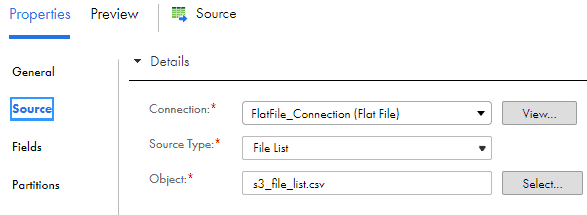
1. In the Source transformation, select your source flat file connection with Source Type as File List.
2. Select the dynamic list file created by script as Source Object.
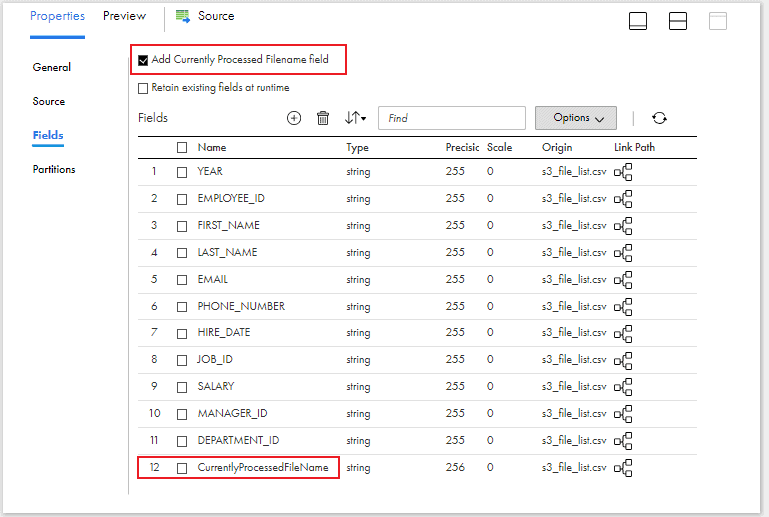
3. Under the Fields section, select Add Currently Processed Filename field option. Selecting this option creates an additional field in the fields list.
4. Complete the rest of the mapping as per your requirement and map the source fields to the target.
5. Create a Mapping Task for your mapping. In the Schedule tab, under Post-Processing Commands, add the command to delete the files copied from s3 to local directory.
-- Windows:
del <LOCAL_DIR>\<FILE_PATTERN>
-- Linux:
rm –f <LOCAL_DIR>/<FILE_PATTERN>4.5. Build a Task flow to integrate all the processes
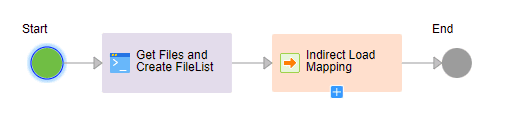
In the taskflow, add a Command Task step to call the script discussed in step-3 which copies files from s3 to local directory and creates a dynamic file list. Add a Data task step after the command task step to trigger the mapping task which performs the Indirect file loading of files copied from s3 to local directory and removes them after successfully processing them.
5. Alternate Approach
As discussed in the Indirect file loading article, the Indirect file loading can be performed using Command Source Type.
In the mapping,
- Select the Source Type as Command.
- Create a template file with same header structure as the s3 files and pass it as Sample Object in the source transformation.
- Create a simple script (shared below) which would list all the files in the directory that match the pattern passed.
- Under Command, provide the script name along with the directory path.
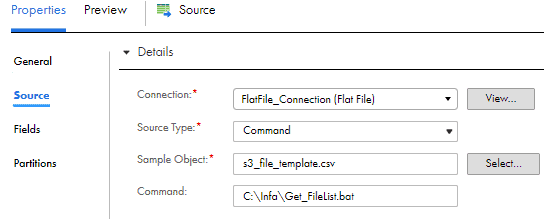
Contents of Get_FileList.bat :
@echo off
cd C:\Infa
dir /b s3_emp_*.csvContents of equivalent script in Linux, Get_FileList.sh :
cd /Informatica/Scripts/
ls s3_emp_*.csvIn this process there is no need to create a script to copy the files from s3 to local directory. Instead, in the mapping task,
- Pass the AWS S3 CLI command to copy the s3 files to local directory as Pre-Processing Command.
- Pass the system command to delete the files in local directory as Post-Processing Command.

6. Conclusion
To summarize, as the Amazon S3 v2 connection do not provide the option to add the field which provides the currently processed file name, we use AWS CLI commands to copy the files from s3 to local directory and use the Flat file connection capabilities to populate the filename value.
Now you might be wondering, just like in alternate approach why can’t we make use of pre-processing command option in the mapping task to call the CLI commands to copy the files and create the file list? The reason to use a command task is, when the mapping task with file list is triggered, the data integration service starts looking for the files mentioned in the list file even before running the pre-processing command as a validation step. As the files listed in the list file were deleted at the end of previous run, the job fails.
Subscribe to our Newsletter !!
Related Articles:

There are multiple ways of implementing Indirect File loading technique in Informatica Cloud. Find out details in the article.

Learn how to read multiple files from Amazon S3 and write to single target in IICS using manifest file through Indirect Loading method.

The process to read JSON files from AWS S3 using IICS is different reading from Secure agent machine. Learn how to read JSON files from AWS S3 using different methods.

