
Introduction
A Slowly Changing Dimension (SCD) is a dimension that stores and manages both current and historical data over time in a data warehouse. The Slowly Changing Dimension Type 2 is used to maintain complete history of a record in a target. When the value of a chosen attribute of the record changes, the current record is closed and made Inactive. A new record is created with changed data values and is considered active record.
The active and inactive records are identified by maintaining the effective start and end date where the active records do not have a corresponding end date. This also helps to track the time period between which the record is active.
The following example illustrates implementation of SCD Type-2 using Dynamic Lookup in Informatica Cloud Data Integration.
Consider below Employees table as the target database table.

- Employee_Key is the surrogate key which increments plus one for each record inserted into the table.
- Every record has a CHECKSUM value which is unique sequence representing the data of the record. For any change in the data, the checksum value differs and helps in identifying if there is any change in the record data.
- Records with maximum end date 9999-12-31 represent ACTIVE records.
The mapping to load data into Employees table should handle the following scenarios.
- When a new employee record is received from source, it should be inserted into the table.
- When an existing employee record without any change is received, it is dropped in the mapping.
- When an existing employee record with changes is received, the existing record in target table is made INACTIVE by updating the END_DATE with system date value. The record with updated data is inserted as a new record in the table.
Consider below as the source data that needs to be processed into the Employees table.
| EMP_ID | EMP_NAME | EMP_SALARY | DEPT_ID |
| 100 | Jennifer | 9000 | 10 |
| 102 | Henry | 7000 | 20 |
| 102 | Henry | 10000 | 20 |
If you use static cache in this scenario, the first record is considered as update and processed correctly. The second record is dropped in the mapping as there is no change in the data. The third record is considered as Insert and a new record is created in the target. The fourth record however should be an update will still be considered as Insert as the row is not present in the static cache when the mapping started.
This scenario where duplicates are expected in the source data can be handled using Dynamic lookup cache.
Configuring a Dynamic Lookup – Mapping Example
The below mapping illustrates the design of SCD Type-2 implementation in Informatica Cloud Data Integration.
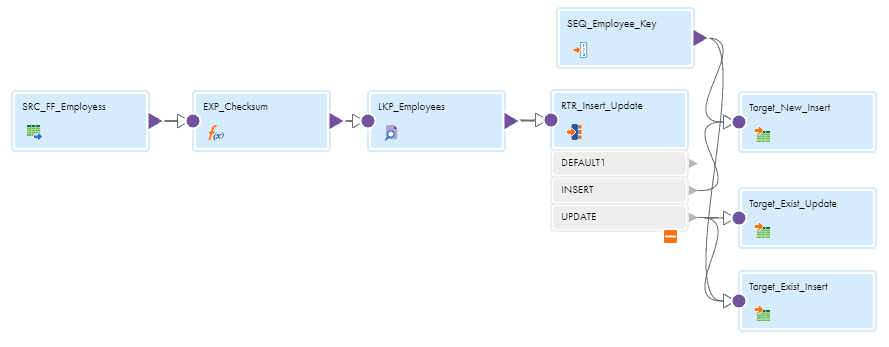
Before proceeding further, to understand all the advanced properties available in Lookup transformation to implement Dynamic lookup cache, refer the article Dynamic Lookup Transformation In Informatica Cloud.
Read the source data in the source transformation and calculate the Checksum value using a MD5 function by passing the required source fields in an expression transformation.
O_CHECKSUM = MD5(EMP_ID||EMP_NAME||EMP_SALARY||DEPT_ID)Configuring Lookup Transformation
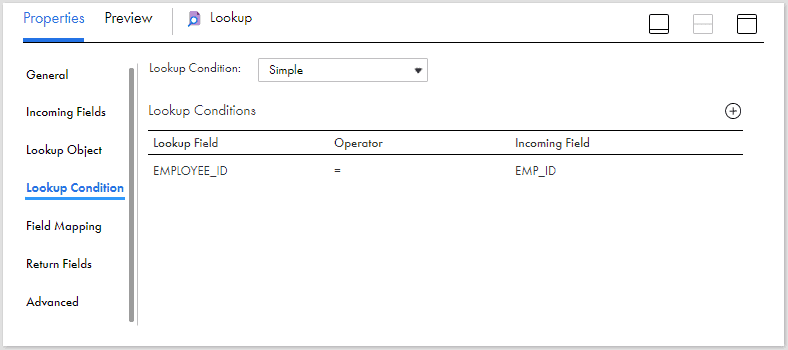
Pass the data to a Lookup transformation. Select the Employees table as the lookup object. Under Lookup condition tab select the condition based on employee id fields from source and lookup as shown below.
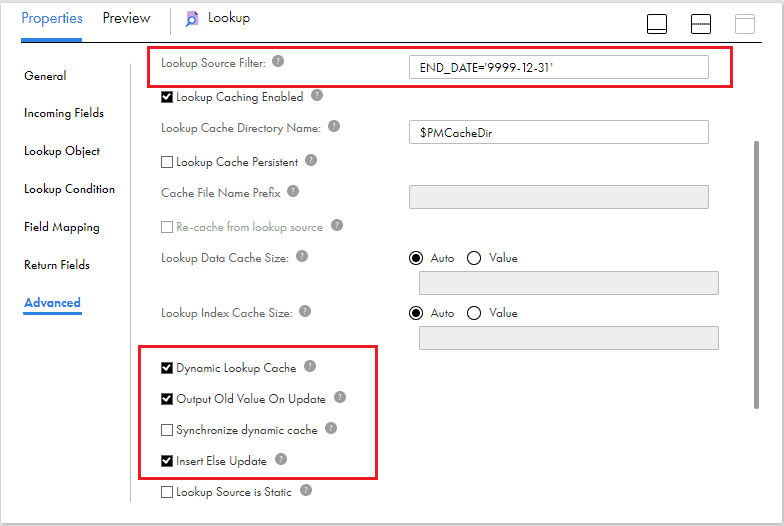
In the Advanced tab of lookup transformation, enable Dynamic Lookup Cache, Insert Else Update and Output Old Value On Update properties. Enter the Lookup Source Filter as END_DATE=’9999-12-31′ since we need to consider only the active employee record for any update.
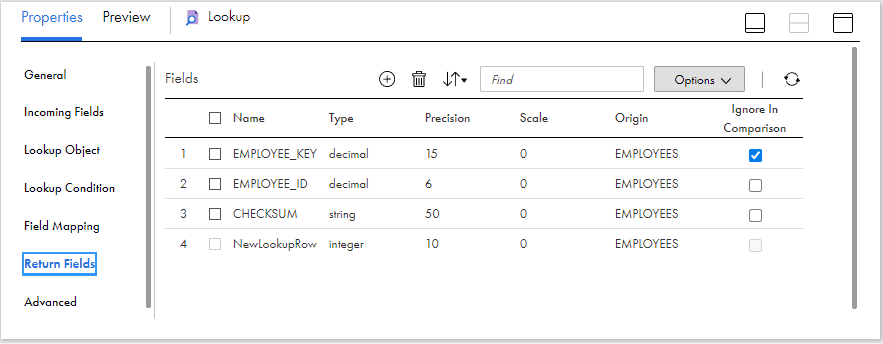
Under the Return Fields tab, delete the unwanted fields which are not required for comparison. You can still keep them without deleting by selecting fields to Ignore in Comparison. The field NewLookupRow is included by default when Dynamic lookup cache is enabled.
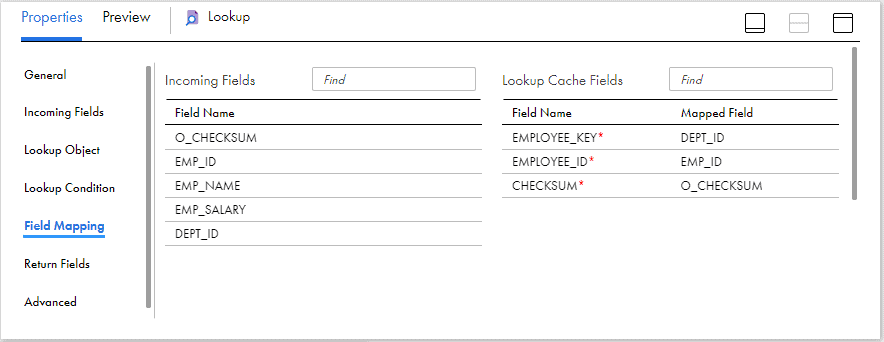
Under Field Mapping tab, map the fields Incoming fields with Lookup cache fields to identify if the record already exist in the lookup cache. If exists already, is there any change in the data. We are using Employee ID and Checksum fields to find if record exists and there is any change in the data.
Note: Employee_Key is not required in the comparison. In fact we do not have any field from source to compare the key value as it is generated in the later stage of mapping using a sequence generator. Hence there is no way we have the key value to pass to compare the record. Since we already selected the field to Ignore in Comparison, the field can be mapped with any incoming field and it will be just ignored.
The output from the lookup transformation after processing the source data will be as below. The Source Rows indicates the fields read and calculated from source data. The Lookup fields indicate the output value the lookup returns from cache.
Related Article: Dynamic Lookup Transformation In Informatica Cloud
Understanding Lookup Transformation Output

Let’s break it down and understand the output from lookup transformation.
- Since the salary of employee ID = 100 is changed and there is a mismatch in the checksum value, the record is updated in the dynamic lookup cache and the NewLookupRow value is set to 2.
- As no data has changed for employee ID = 101, the record is marked as unchanged and no changes are done to dynamic lookup cache. The NewLookupRow value is set to 0.
- As the employee record with ID = 102 is not existing, the record is inserted into the dynamic lookup cache and the NewLookupRow value is set to 1.
- Since the employee record with ID = 102 is already cached in the dynamic lookup and the record is found to be updated, the record is updated in the dynamic lookup cache and the NewLookupRow value is set to 2.
Since we have enabled the Output Old Value On Update advanced property, the lookup returns the checksum value already present in the cache before updating the dynamic cache with incoming row value.
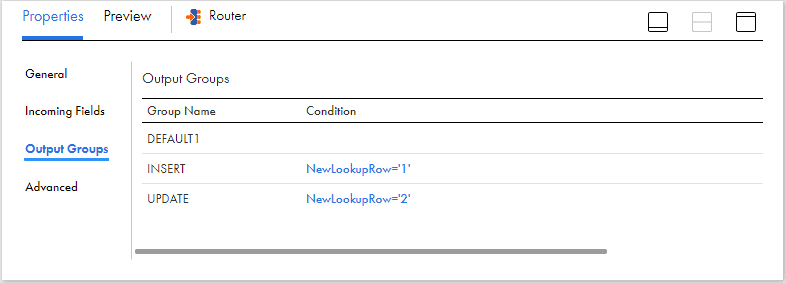
Configuring Router Transformation
The records from Lookup transformation are passed to Router transformation where the new records are routed to INSERT group and the updated records are routed to UPDATE group based on the NewLookupRow value.
The rows from the INSERT group are loaded directly into the employees table. The rows from the UPDATE group are routed to two different targets as shown in image. In one of the target, the end_date in the employee record is updated with current date value to make it Inactive. The record is identified based on the checksum value returned from lookup. In the other target, the record from the UPDATE group is inserted straight into the employees table with the incoming updated employee data and checksum value.
Target table data after the load
The data in the Employees table after the source data is processed is as below.

Jennifer’s record is made inactive and new record with updated salary is inserted. Michael’s record is unchanged. Henry’s record is inserted into the table first. When an another record comes with updated data, the existing record is made inactive and the new record with updated data is inserted in same mapping run.
Related Articles:





Thanks lot for explanation. I have one doubt here why we are using seq generation transformation, because there is no use in mapping
To generate surrogate keys for Key Column
Thanks lot for explanation.
I have one doubt here why we are using seq generation transformation, because there is no use in mapping
To generate surrogate keys for Key Column