
While working with large data sets in ETL the most efficient way is to process only the data that should be processed which is either newly added or modified since the last run time rather than processing entire data every run.
This method of processing the newly added or modified data usually takes less time to run, involves less risk and preserves the historical accuracy of the data.
Let’s discuss how it can be implemented in Informatica Cloud (IICS).
1. What is Incremental data loading?
Incremental data loading is the process of loading the selective data which is either updated or created new from source system to the target system.
This is different from full data load where entire data is processed each load.
2. Benefits of Incremental data loading
- Working on selective data from source system reduces the overhead on ETL process, there by reduces the overall run time.
- Any ETL load process is prone to errors or failing because of multiple reasons. As only selective data is processed the probability of risk involved is reduced.
- The historical accuracy of the data is preserved. There by it is easy to track the data processed over a particular period of time.
3. Implementation of Incremental data loading in IICS
There are multiple ways of implementing Incremental data loading in Informatica Cloud and each method has its own advantages.
Before discussing each method in detail let us set up the source and target which will be used in the examples discussed below
3.1 Setting up Source and Target tables for the demonstration
Below is the source table EMP containing the employee information. The fields Created_date and Modified_date are defaulted to systimestamp meaning whenever a record is created the system timestamp gets inserted automatically for these fields.
CREATE TABLE EMP (
EMPLOYEE_ID NUMBER(6,0),
NAME VARCHAR2(20 BYTE),
SALARY NUMBER(8,2),
DEPARTMENT_ID NUMBER(4,0),
IS_ACTIVE VARCHAR2(1 BYTE),
CREATED_DATE TIMESTAMP DEFAULT SYSTIMESTAMP,
MODIFIED_DATE TIMESTAMP DEFAULT SYSTIMESTAMP
);
But we need the Modified_date to change whenever the record is modified. To achieve that lets create a simple trigger on that field.
CREATE OR REPLACE
TRIGGER HR.MODIFIED_DATE_TRIGGER
BEFORE INSERT OR UPDATE ON HR.EMP
FOR EACH ROW
BEGIN
:new.MODIFIED_DATE := SYSTIMESTAMP;
END;
After this whenever a record is created, systemtimestamp value gets loaded for both Created_date and Modified_date. But when something gets updated for the record, the created_date remains same but the Modified_date changes to current timestamp.
Let’s insert some sample data into the table.
INSERT INTO EMP(EMPLOYEE_ID,NAME,SALARY,DEPARTMENT_ID,IS_ACTIVE) VALUES(100,'Jennifer',4400,10,'Y');
INSERT INTO EMP(EMPLOYEE_ID,NAME,SALARY,DEPARTMENT_ID,IS_ACTIVE) VALUES(101,'Michael',13000,20,'Y');
INSERT INTO EMP(EMPLOYEE_ID,NAME,SALARY,DEPARTMENT_ID,IS_ACTIVE) VALUES(102,'Pat',6000,20,'Y');
INSERT INTO EMP(EMPLOYEE_ID,NAME,SALARY,DEPARTMENT_ID,IS_ACTIVE) VALUES(103,'Den', 11000,30,'Y');
INSERT INTO EMP(EMPLOYEE_ID,NAME,SALARY,DEPARTMENT_ID,IS_ACTIVE) VALUES(104,'Alexander',3100,30,'Y');
INSERT INTO EMP(EMPLOYEE_ID,NAME,SALARY,DEPARTMENT_ID,IS_ACTIVE) VALUES(105,'Shelli',2900,30,'Y');
INSERT INTO EMP(EMPLOYEE_ID,NAME,SALARY,DEPARTMENT_ID,IS_ACTIVE) VALUES(106,'Sigal',2800,30,'Y');
INSERT INTO EMP(EMPLOYEE_ID,NAME,SALARY,DEPARTMENT_ID,IS_ACTIVE) VALUES(107,'Guy',2600,30,'Y');
INSERT INTO EMP(EMPLOYEE_ID,NAME,SALARY,DEPARTMENT_ID,IS_ACTIVE) VALUES(108,'Karen',2500,30,'Y');
select * from EMP;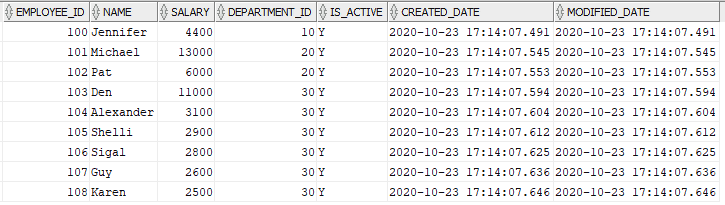
NOTE: The Created_Date and Modified_Date are auto populated in the EMP table.
Let us now create a target table to load the data and observe the incremental changes.
CREATE TABLE EMP_COPY(
EMPLOYEE_ID NUMBER(6,0),
NAME VARCHAR2(20 BYTE),
SALARY NUMBER(8,2),
DEPARTMENT_ID NUMBER(4,0),
IS_ACTIVE VARCHAR2(1 BYTE)
CREATED_DATE TIMESTAMP,
MODIFIED_DATE TIMESTAMP
);
NOTE: The Created_date and Modified_date are not assigned any default values like in source table.
3.2 Implementing Incremental Data Loading using IICS System Variables
IICS provides access to following system variables which can be used as a data filter variables to filter newly inserted or updated records.
$LastRunTime returns the last time when the task ran successfully.
$LastRunDate returns only the last date on which the task ran successfully.
For more information on these system variables, check out this Informatica article.
3.2.1 Mapping development steps
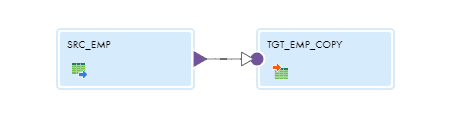
Select the table EMP as source and define the filter condition on the field Modified_Date as shown below
The system variable $LastRunTime is stored in GMT timezone.
The data in the oracle table EMP is stored in IST.
So if the data we are processing is not stored in GMT timezone it is required to add the conversion factor to the variable.
As IST is five and half hours ahead of GMT timezone, the oracle conversion of 5.5/24 is added.
For the initial run the value of $LastRunTime by default will be ‘1970-01-01 00:00:00’
In the target transformation select EMP_COPY as target as shown below and map the source fields under Field Mapping section and save the mapping.
3.2.2 Demonstration
Once the mapping is saved and triggered, all the 9 records from EMP will be loaded into the EMP_COPY table.

The query fired by Informatica in session log will be as below.
SELECT HR.EMP.EMPLOYEE_ID,
HR.EMP.NAME,
HR.EMP.SALARY,
HR.EMP.DEPARTMENT_ID,
HR.EMP.CREATED_DATE,
HR.EMP.MODIFIED_DATE
FROM HR.EMP
WHERE EMP.MODIFIED_DATE > to_timestamp('1970-01-01 00:00:00','YYYY-MM-DD HH24:MI:SS')+5.5/24Now let’s update a record and see how the mapping behaves.
UPDATE EMP SET IS_ACTIVE = 'N' where EMPLOYEE_ID = '108';We can now observe that the Modified_date is updated for ID 108 in EMP table
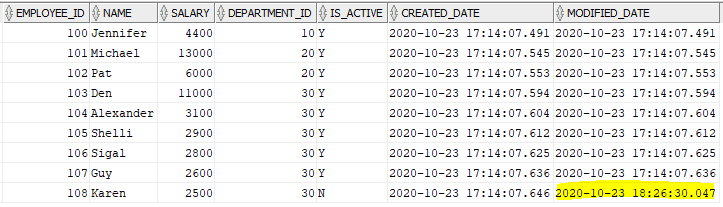
Let us trigger the mapping and see the query fired by Informatica and data processed.
Only one record is processed as expected.

The query in session log is as below.
SELECT HR.EMP.EMPLOYEE_ID,
HR.EMP.NAME,
HR.EMP.SALARY,
HR.EMP.DEPARTMENT_ID,
HR.EMP.CREATED_DATE,
HR.EMP.MODIFIED_DATE
FROM HR.EMP
WHERE EMP.MODIFIED_DATE > to_timestamp('2020-10-23 12:50:17','YYYY-MM-DD HH24:MI:SS')+5.5/24The time conversion of to_timestamp(‘2020-10-23 12:50:17′,’YYYY-MM-DD HH24:MI:SS’)+5.5/24 translates to 2020-10-23 17:50:17. This is the exact time we triggered the job first time when 9 records were processed.
It is important to understand that $LastRunTime stores the task last run time. Not the maximum last modified date value from the table.
Hence the timezone conversion is mandatory.
3.3 Implementing Incremental Data Loading using IICS Input-Output Parameters
3.3.1 Mapping development steps
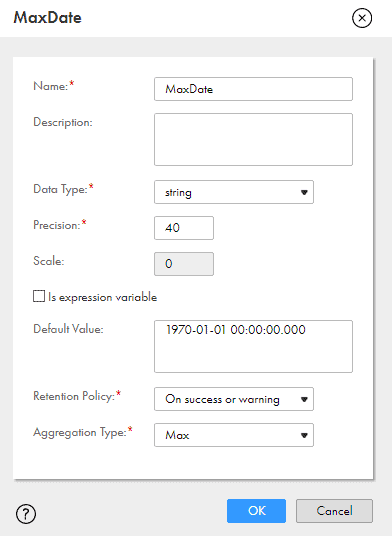
Create a new mapping and from the Parameter panel in the mapping create an Input-Output Parameter.
Enter the name of the parameter, data type as string of size 40 and the default value as shown below. Leave the rest of the properties as it is and click OK.
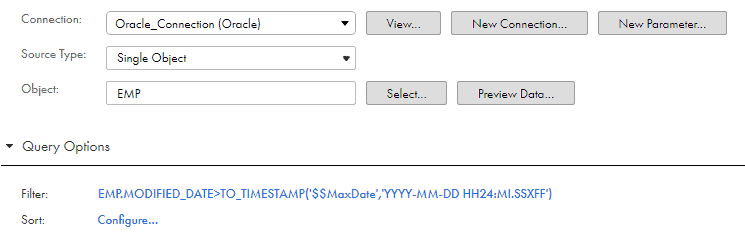
Under Source select EMP as source object and define the filter as shown below.
Filter: EMP.MODIFIED_DATE>TO_TIMESTAMP(‘$$MaxDate’,’YYYY-MM-DD HH24:MI.SSXFF’)
Map the source fields to an Expression transformation. In Expression transformation create a new field and assign the value as below.

The target configuration is same as we discussed in previous method. Select EMP_COPY as target and do the required Field Mapping.
Create another Flat File target and just map OutMaxDate field into the target from Expression and save the mapping.
Now let us understand step by step what we have done here
- We have created an Input-output Parameter which is same as a variable in Informatica Powercenter of type string and we have defined a default value.
- In the source we have defined a filter on Modified_date field based on the variable we created. As the variable is of type string we are converting it into datetime format using TO_TIMESTAMP function.
- For the initial run the mapping runs with default value we defined for MaxDate variable which is 1970-01-01 00:00:00.000
- In the next step we are calculating the maximum value of the Modified_date field out of all records using SETMAXVARIABLE function and assigning it to the MaxDate variable.
- As the MaxDate variable is of type string we are converting Modified_date into string using TO_CHAR function.
- So by the end of the mapping the variable we created will be assigned with the maximum Modified_Date value out of all the records which will be used in the source query of next run.
- We have created couple of targets. One our primary target to load the data and other one just to see how the MaxDate value gets changed while processing each record.
The final mapping will be as shown below
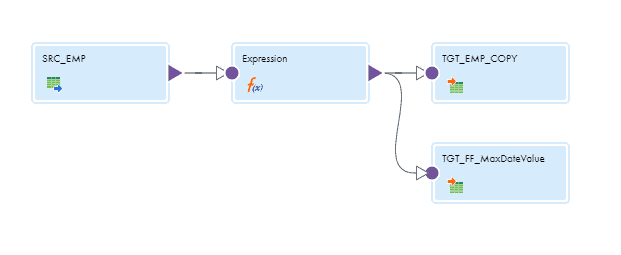
3.3.2 Demonstration
Before starting the mapping I have reset the entire data in EMP table to have a fresh start. The data is as below.
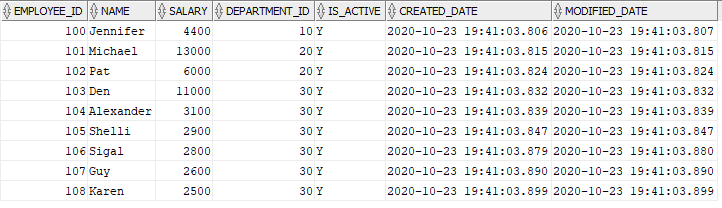
Let us trigger the mapping and understand how the mapping behaves. Below are the results after the successful completion of the mapping.
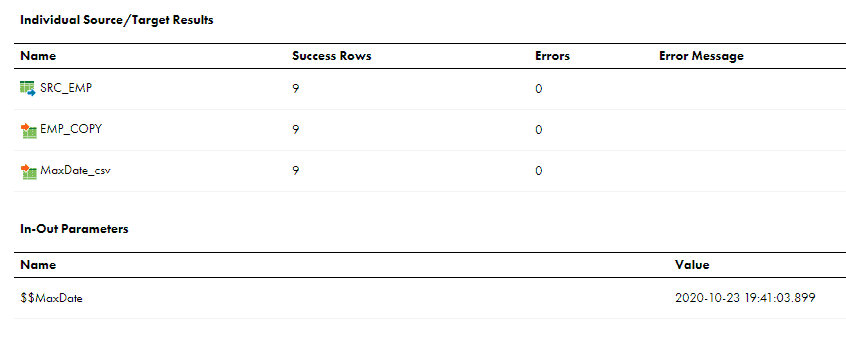
All the 9 records are processed in the initial load and we can also see the value of the Input-Output parameter MaxDate updated for next run which is maximum Modified_date value from our source data at the end of mapping.
You can also check how the MaxDate value varied for each record by opening the CSV file created by the mapping.
To understand the incremental behavior let us update a record in source.
UPDATE EMP SET IS_ACTIVE = 'N' where EMPLOYEE_ID = '108';The data in source table is modified as below.
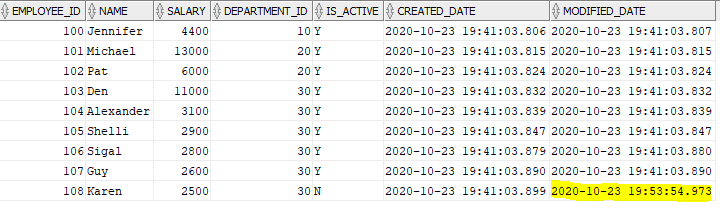
Let us retrigger the mapping and check the results
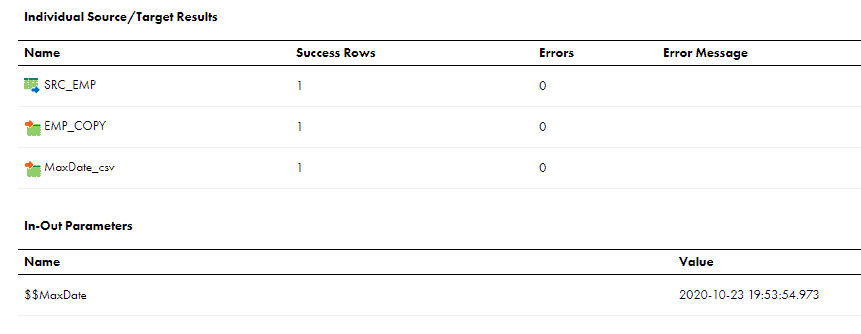
Only one record from source is processed and the MaxDate value also updated which will be used in the source filter for next run as expected.
ProTip: Make sure the field where you assign the Max date value using SETVARIABLES is mapped to one of the field in the target transformation.
3.4 Implementing Incremental Data Loading using IICS Input Parameters and Parameter File
3.4.1 Parameter File creation
Let us begin with creation of parameter file first.
Create a parameter file Incremental_loading.param and enter the following text in the file and place it in your parameter file location.
$$DateFilter=1970-01-01 00:00:00.0003.4.2 Mapping development steps
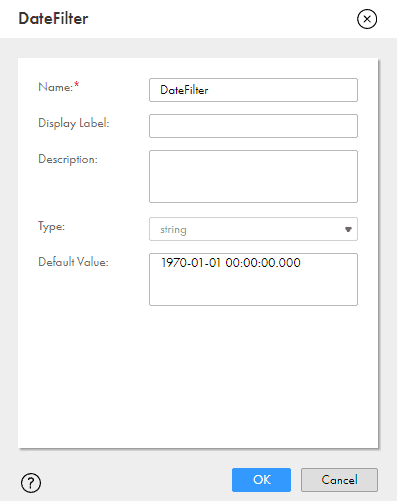
Create a new mapping and from the Parameter panel create a new Input Parameter.
Enter the name of the parameter and the Default Value as shown below and click OK.
Unlike previous method we need to calculate the maximum Modified_Date for each run by implementing a mapping logic and save it in the parameter file which can be used by next run to filter the new and updated records.
Select the table EMP as source.
Define the filter condition on the field Modified_Date as shown below.
Also sort the records based on Modified_date so that the record with maximum Modified_date is read at the end.
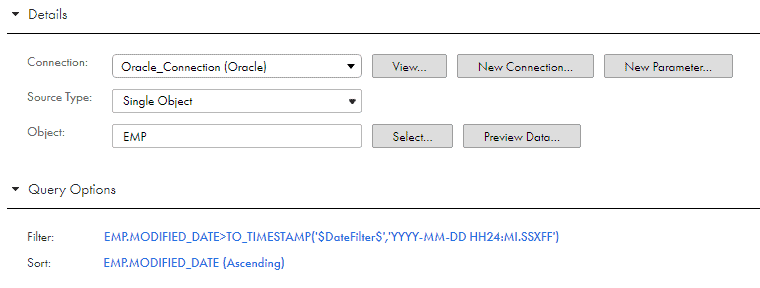
NOTE: The IICS Input Parameters are represented with $ at starting and the end of the parameter name.
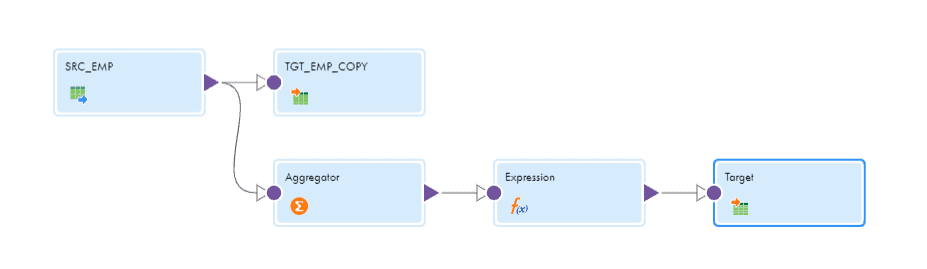
Map the records from source to target EMP_COPY and complete the Field Mapping.
Map the records from source to an Aggregator transformation. No action required in the aggregator.
Since no Group By fields are selected, only the last record from source passes from aggregator which contains the maximum Modified_date value.
Map the fields from aggregator to an expression transformation.
In Expression transformation create an output field Parameter_Value and assign value as ‘$$DateFilter=’||TO_CHAR(MODIFIED_DATE,’YYYY-MM-DD HH24:MI:SS.MS’)

This Parameter_Value field which will be calculated here will be written to a text file.
Map the fields from expression to a target transformation. In the target select your Flat File connection and select Create New at Runtime and provide the target file name.
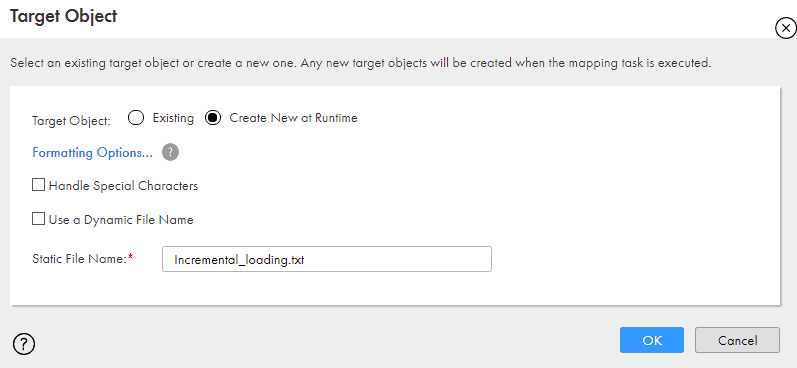
So whenever the mapping runs the target file is over written with new value of maximum Modified_Date.
The final mapping will be as follows
3.4.3 Mapping Task development steps
Create a Mapping task from the mapping by clicking on the three dots at the top right corner.

In the Definition step provide the name of the mapping task, select the Runtime Environment and click Next.
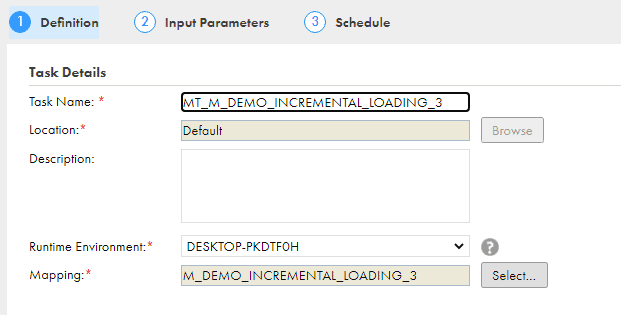
In the Input Parameters tab enter the value of input parameter DateFilter as $$DateFilter and click next.
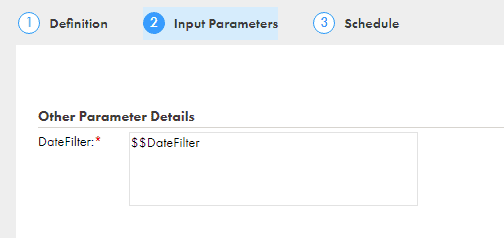
In the Schedule tab enter the Parameter File Directory and Parameter File Name

3.4.4 Script creation
Now the final step is to create a Script which reads the data from the flat file (Incremental_loading.txt) we are creating in the mapping and write it to the parameter file (Incremental_loading.param).
The functionality of the script should be
- Check if the flat file (Incremental_loading.txt) has data.
- If yes copy the flat file (Incremental_loading.txt) as Parameter file (Incremental_loading.param).
- Else do nothing so that the previous Modified_date value is still retained in parameter file.
The requirement of script is explained during demonstration with an example.
If you are in windows create a batch script as below and name it copyfile.bat

Enter the script details in the Post–Processing command of the Mapping task and save it.
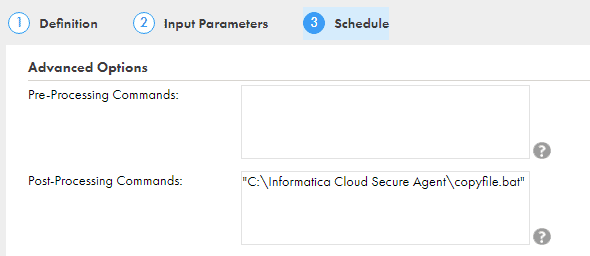
Now we are all set with the Mapping, Mapping Task, Parameter file and Script.
3.4.5 Demonstration
Let us understand how everything works through a demonstration.
I have again reset the data in the source table and below is the data in EMP table.
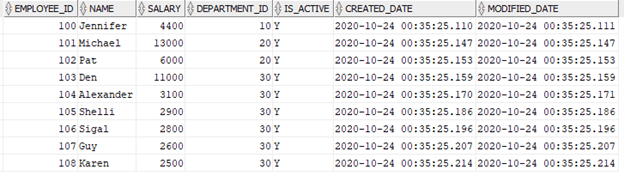
Understand the parameter file Incremental_loading.param is created with default value and the output file Incremental_loading.txt is not created yet before the initial run.
Run the Mapping Task.
All the 9 records are processed from source and loaded into target as expected and the value written to the flat file target.
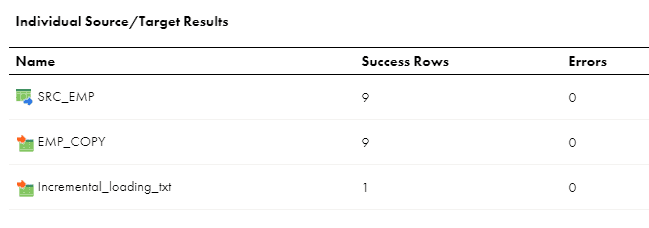
Let us observe the contents of Incremental_loading.txt and Incremental_loading.param after the initial run

So the maximum Modified_date value is loaded into the text file by the mapping and the Script copied it to the Parameter file.
So why not use the output text file as parameter file? Why we need a script again to copy the contents to a parameter file?
Let us understand the reason with a demo. Let’s retrigger the mapping. As there is no change in the data, no records should be fetched from source.
As expected no records are read from source.

Check the contents of Incremental_loading.txt and Incremental_loading.param after the run.

As no data is processed, the output text file data is over written and the data present in it is lost.
The script checks if data is present in the text file and as no data is present it, the script exits doing nothing there by data in the Parameter file is retained.
When the data is modified in source table the mapping could still read from parameter file and process as usual.
This is the reason script is needed which helps in retaining the parameter value when no data is processed.
4. Conclusion – Which method should I Implement?
These are the different ways Incremental data loading can be implemented in Informatica Cloud.
The first method implementation is easy but you need to be careful with the time zone conversion. This method performs incremental data loading based on the last run time of the task and not the maximum modified date from the source data.
The second method gives you flexibility to store the maximum date from the source data to perform incremental data loading rather than task run time. In the latest release Informatica also provided a feature to update the stored maximum date value. So, in case if you have to run the mapping from an older date value, you can edit the value of In-Out parameter value from mapping task.
The third method implementation is lengthy compared to other two methods but since it reads data from parameter file, it gives you flexibility to change the parameter values easily without modifying the Informatica code. In first method the parameter values cannot be edited as they are stored in Informatica repository and the second method requires editing the mapping task for any adhoc run.
It all comes down to your requirement to choose which method to implement.
Subscribe to our Newsletter !!


Thank you. Very well explained, really appreciate you time and effort, Please keep up the good work
Thanks Waseem. Glad you liked it!!
Awesome efforts and detailed explanation, very helpful. Please post in future too.
Thanks Sucharitha. Glad you liked it!!
Hi,
Very helpful and detailed explanation.
I have migrated code to production and mapping is running everyday using $lastruntime parameter. I would like to know what will be the value of this parameter if the same mapping is migrated again with little modification. The value of $lastruntime will be the last execution time of the task or it will reflect initial value.
Informatica will restore last execution time in Production.
Will this work Source as Flat file ?
In Source transformation, Filter and Sort options are not supported for Flat File connection type. So you have to read full data every time from source and then apply the incremental logic using the Filter transformation.
The image screenshots in this post are not showing up. Could you please check?
I don’t see any issue with images. Could you please try from another browser and confirm?
Thank you very much for your sharing! I have a question for the option 2, by using In-Out Parameter. Can we using this option for multiple tables incremental load as we can schedule the mapping using task flows? As I know the In-Out parameter cannot work concurrently, and it might cause an issue when the tables are running in parallel?
Thanks again!
Thank you!! I am not completely clear about your query. But if your requirement is to get the incremental data from multiple tables in a mapping, create a separate In-Out parameter for each flow.
Some case we need to apply incremental for hundreds of tables, so by using this solution we need to create hundreds of mapping, so that I want to know whether can we have a dynamic solution like using parameterized mapping then can re-use in the mapping task and task flows. Do you have any idea on this problem? Thanks!
Yes.. you can build a completely parameterized single mapping and use that in multiple mcts for incremental loading.
The incremental value you calculate using set variable will be local to each mct.
thanks a lot for the detailed explanation. I liked it very much, especially the reason for keeping two files (incremental and param).
Thank you!!👍
This is great work.Pls create similar contents for IDQ as well. That will be very helpful for preparing for interviews. Thank you
Thank you Its Really Good and Helpful Information and Its also Very Important Topic