Flow Run Order
When there are individual data flows in a mapping, the order in which the data integration process the flows can be configured in Informatica Cloud Data Integration using Flow Run Order. This is analogous to the Target Load Plan in the Informatica Powercenter.
A flow is a collection of all connected sources, transformations and targets in a mapping. You can have multiple flows in a mapping. Specify the flow run order when you want Data Integration to load the targets in different flows in the mapping in a particular order.
Flow Run Order Use cases
- Use Flow run order when the data of one target is dependent on the data of another target in the mapping.
For example, if a target table in a data flow is the source in the another data flow, the flow which loads data into the table needs to be executed first which can be controlled using flow run order. - Use Flow run order to maintain referential integrity when updating tables that have Flow run order primary or foreign key constraints.
For example, the employees table which contains the department information needs to loaded only after the departments table is loaded first because of primary key – foreign key relationship between the tables. The flow which loads data into departments table can be loaded first using the flow run order. - Use Flow run order to control the execution of a data flow in a mapping based on the result of another flow.
For example, you want to load data from a flat file into database only if the flat file has data else abort the process. In that case create a data flow which reads the record count of the flat file and aborts the mapping if the file is empty using the built-in Abort function with custom error message. Execute this data flow first using flow run order. - Flow run order can be specified with any target types in the mapping.
Configuring the Flow Run order
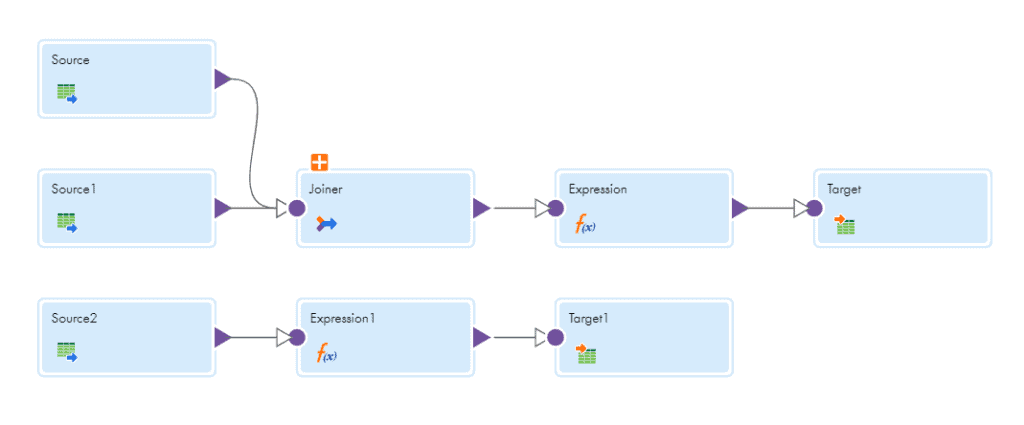
Consider the below mapping as an example with two separate data flows. Flow-1 reads the data from Source and Source1 and loads data into Target. Flow-2 reads data from Source2 and loads data into Target1.
In order to specify the flow run order, follow below steps
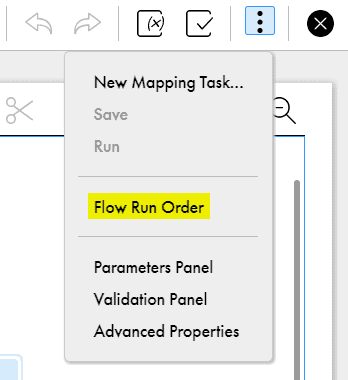
- In the mapping designer, click on Actions (three vertical dots present on the top right top corner of the mapping designer) and select Flow Run Order.
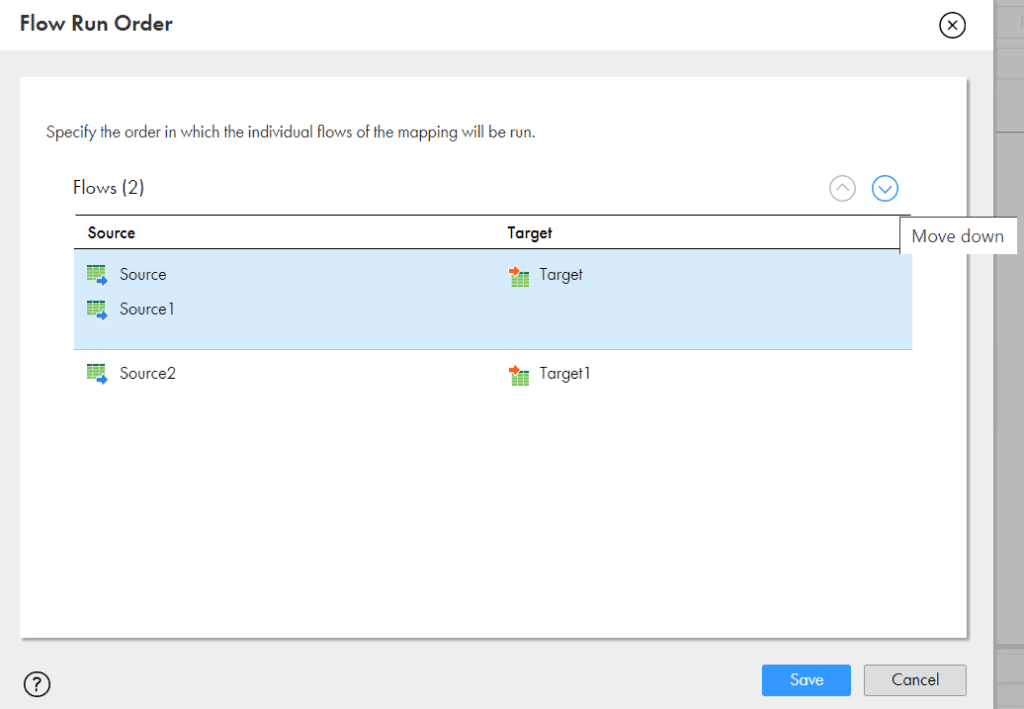
- In the Flow Run Order dialog box, select a data flow and use the arrows to move it up or down to set the desired execution order and click Save.
Points to remember before configuring the Flow Run order
- If you add a new data flow to the mapping after you configured the flow run order, the new flow is added to the end of the flow run order by default.
- If there are multiple targets in a single data flow, the both targets are loaded concurrently.
- If one of the data flow in the mapping fails, the mapping completely fails and stops executing the other data flows in the mapping. If the mapping is retriggered, the data integration starts executing from flow-1 again.
- If the above mentioned scenario is not a desired, create a separate mapping for each data flow and control the execution order of their mapping tasks through Task Flows or Linear Task Flows available in data integration.


