
1. Introduction to Impact Analysis Tool
How do you perform Impact Analysis in your IICS Data Integration projects? Is it manual?
If there is a Change Request to make changes to a particular database table or a field, how do you find all the impacted mappings in Informatica Cloud which are using that table?
If there are hundreds of mappings, it takes a lot of effort to sweep through all the mappings and still we might be missing few.
It is always best to automate the process so we can be sure that we are not missing out anything and it also saves a lot of time.
In this article let’s discuss how to build an Impact Analysis tool in Informatica Cloud which helps in this scenarios.
2. Steps to access metadata in Informatica Cloud
We have discussed in detail how to read the metadata in Informatica Cloud in a separate article. This automation is built on the same idea by accessing the metadata.
To summarize the above linked article, the metadata in Informatica Cloud can be accessed by
- Use the zip file exported from Informatica Cloud Data Integration as an input to read the metadata.
- Build a script to extract the individual JSON files of Mappings and Mapping Tasks from the exported zip file.
- Build a mapping to read the JSON files using a Hierarchy Parser and generate a report with required details.
The same steps are followed here to read the metadata. But the approach towards fetching the details from the metadata is different.
3. Steps to build Impact Analysis Tool
Let’s start with the details of mapping development.
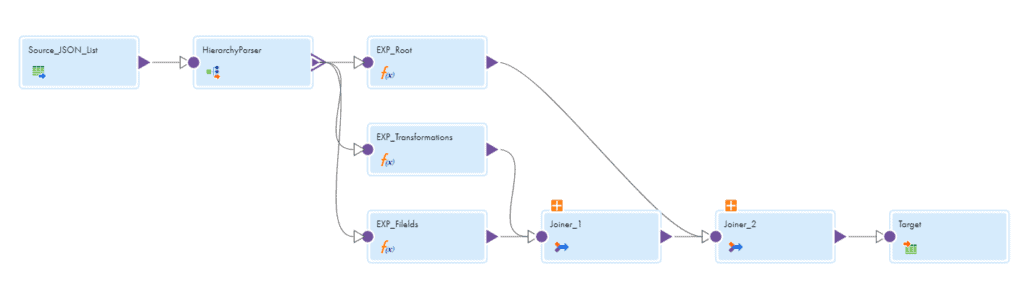
- The Source transformation reads a flat file containing the list of all the mapping JSON files as a source.
- The Hierarchy Parser transformation reads the JSON files one after the other and provides a relational output. A Hierarchical Schema needs to be defined in order to use Hierarchy Parser transformation.
- The Hierarchy Parser parses the JSON input into below relational format.
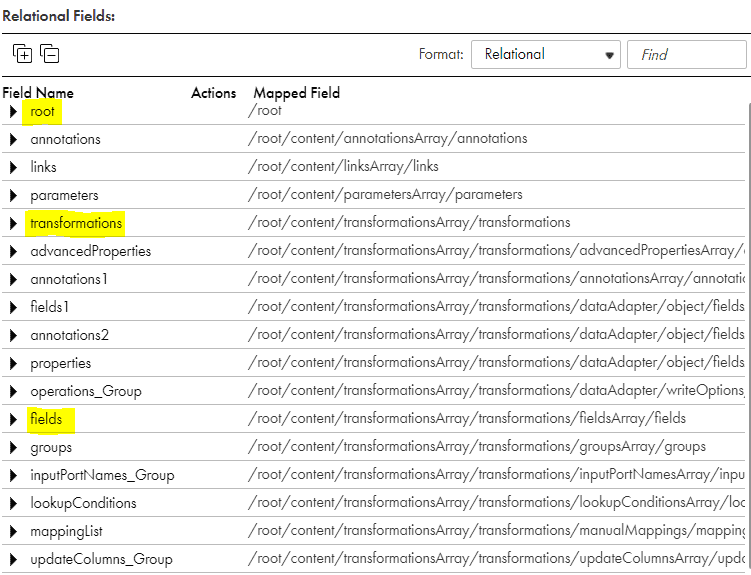
- All the Field Segments are related by Primary Key and Foreign Key relationship created by the Hierarchy Parser transformation.
- When you try to map the data from Hierarchy Parser to any other transformation, Informatica prompts you to select a field segment you want to map as shown below. So you can only map one field segment data to a transformation.
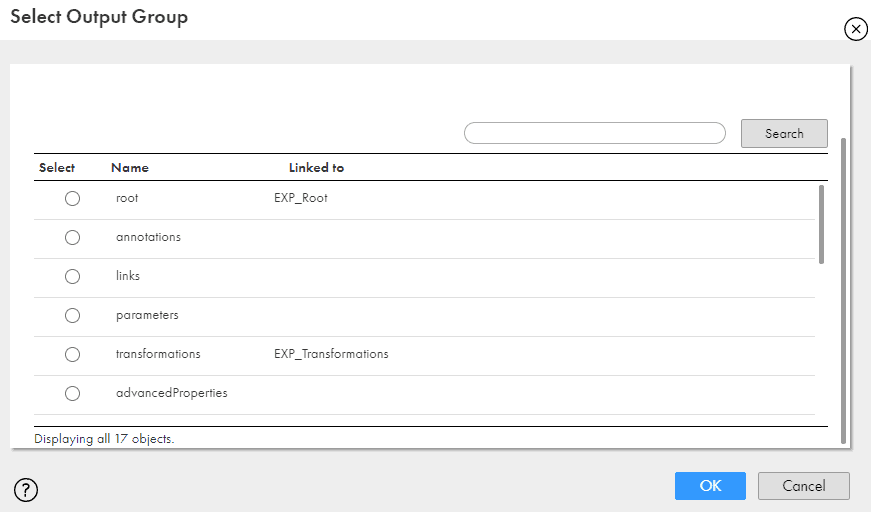
- As you can see I pulled the data from Root, Transformations and Fields which are required for our use case.
- Transformations and Fields expression are joined using the Joiner transformation using the below condition
PK_transformations=FK_transformations. - The output from Joiner_1 and Root expression are joined using the below condition
FK_root=PK_root. - The transformations field segment contains the foreign key FK_Root to connect to Root and its own Primary key PK_transformations to connect to the fields.
- The Root expression is used to fetch the Mapping details like Mapping name.
The Transformation expression is used to fetch the transformation details like transformation name, Object name.
The fields expression is used to fetch the field details like field name, datatype, precision and scale.
Basically we are fetching all the fields of all the transformations of all the mappings we took as an export from IICS.
Confused? For example, if you took five mappings as an export from Informatica Cloud and each mapping has two transformations, a source and a target. Each source and target has 10 columns. So each mapping has 10X2, 20 columns. Overall 20X5, 100 columns in the exported zip from IICS. We can read all these 100 columns and identify exactly from which transformation and mapping they are from.
4. Alternate approach in building the tool
The mapping can be modified according to the requirement. Instead of fetching everything from the exported data, you can add filters to fetch the data of a particular database table or a field by passing the values from a Parameter file.
I prefer to fetch everything and drill down on top of that. It’s just a preference.
5. Additional Use cases
Datatype Validation
This can also be used to build something which can be used for Data Type Validation in Informatica Cloud mappings. As we were able to fetch the datatype, precision and scale of the fields in the same metadata information in the same tool, they can be compared from source to target and check whether they are in sync and report the field names which are not in sync.
6. Conclusion & Course Details
The difference in building the Auto Review Tool for mappings and the Impact Analysis Tool is the data we are trying to read from the Mapping JSON files.
In Auto Review Tool, we are reading data of Transformation properties and in Impact Analysis Tool we are focusing more on the Fields data.
In fact, in the same mapping we are building for Auto review tool, we can accommodate the logic for Impact Analysis tool and get the output in different target in the same mapping.
We have a complete 2.5 hour video course on Udemy explaining how you can build this tool from scratch. Along with a video guided course you will also get instructor support in case you need any help in building the tool at each and every step with a life time access.
The enrollment link to the course:
Informatica Cloud Data Integration – Automation Project


