
Introduction to Snowflake External Tables
In our previous article, we have discussed about external stages which lets you access the data files from external locations like AWS S3, Azure containers and Google Cloud Storage in Snowflake. The data from these files can be accessed by loading them into Snowflake tables.
Snowflake External Tables provides a unique way of accessing the data from files in external locations without actually moving them into Snowflake. They enable you to query data stored in files in an external stage as if it were inside a database by storing the file level metadata.
In this article let us discuss on how to create external tables in Snowflake.
Requirements to create a Snowflake External Table
Consider below points before creating a Snowflake External table
- There must be an external stage created in Snowflake to access the files from external location.
- External tables support external (i.e. S3, Azure, or GCS) stages only. Internal (i.e. Snowflake) stages are not supported.
- You are required to have knowledge of the file format (CSV, Parquet etc).
- Knowing the schema of the data files is not mandatory.
Creating Snowflake External table without specifying column names
For the demonstration purpose we will be using an Azure stage created already in our Snowflake environment. If you are not familiar on how to create Snowflake external stages, refer this article.
The List command allows you to list all the files present in the external location pointed by external stage. The below image shows that we have three employee CSV files present in three different folders in an Azure container.
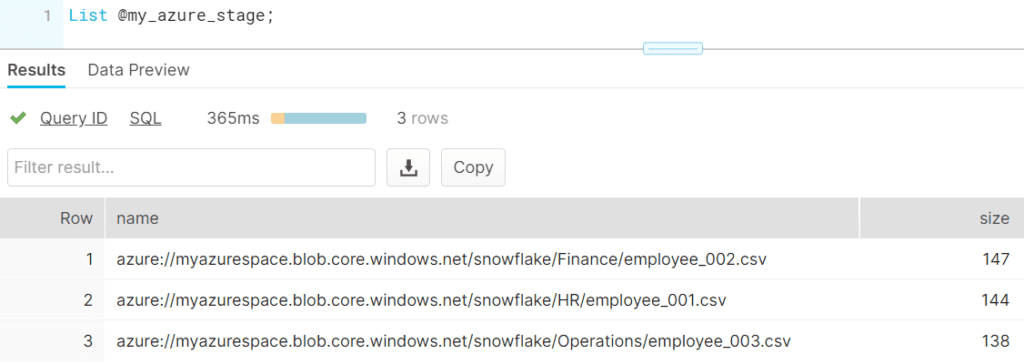
Below are the contents of the each of the files.
HR/employee_001.csv
---------------------------------------------------------
EMPLOYEE_ID,NAME,SALARY,DEPARTMENT_ID,JOINING_DATE
100,'Jennifer',4400,10,'2017-01-05'
101,'Michael',13000,10,'2018-08-24'
102,'Pat',6000,10,'2018-12-10'
Finance/employee_002.csv
---------------------------------------------------------
EMPLOYEE_ID,NAME,SALARY,DEPARTMENT_ID,JOINING_DATE
103,'Den', 11000,20,'2019-02-17'
104,'Alexander',3100,20,'2019-07-01'
105,'Shelli',2900,20,'2020-04-22'
Operations/employee_003.csv
---------------------------------------------------------
EMPLOYEE_ID,NAME,SALARY,DEPARTMENT_ID,JOINING_DATE
106,'Sigal',2800,30,'2020-09-05'
107,'Guy',2600,30,'2021-05-25'
108,'Karen',2500,30,'2021-12-21'The below SQL statement creates an external table named my_ext_table without a column name. The parameters LOCATION and FILE_FORMAT are mandatory.
CREATE OR REPLACE EXTERNAL TABLE my_ext_table
WITH LOCATION = @my_azure_stage/
FILE_FORMAT = (TYPE = CSV SKIP_HEADER = 1)
PATTERN='.*employee.*[.]csv';You can also create external table on a specific file also by specifying the filename along with complete path in LOCATION parameter.
Querying Snowflake External Table
An external table creates a VARIANT type column named VALUE that represents a single row in the external file.
The below query shows the data a single VARIANT column in the external table created in the earlier step. The columns in a CSV file are represented as c1,c2,c3… by default.
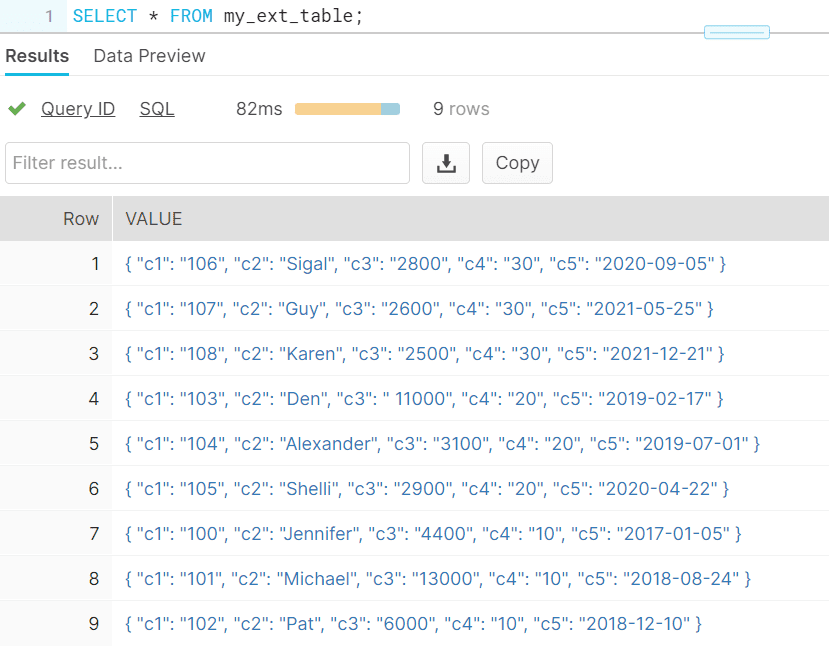
The individual columns can be queried as shown below.
SELECT $1:c1, $1:c2, $1:c3, $1:c4, $1:c5 FROM my_ext_table;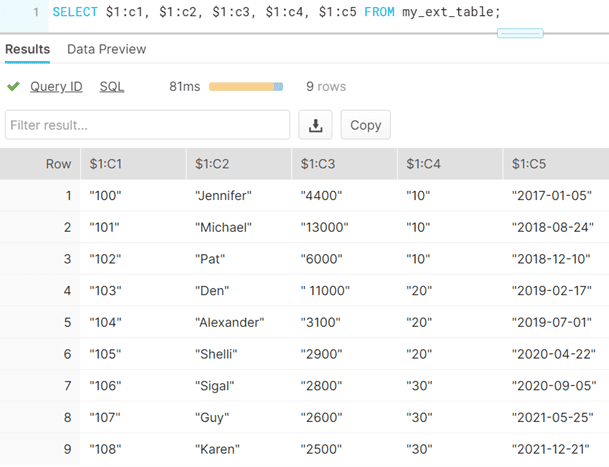
This method of creating external table do not require having knowledge on the schema of the files and allows creating external tables without specifying columns.
Creating Snowflake External table by specifying column names
The below example shows how to create external table with column names by creating a column expression on VALUE JSON object.
CREATE OR REPLACE EXTERNAL TABLE my_azure_ext_table(
EMPLOYEE_ID varchar AS (value:c1::varchar),
NAME varchar AS (value:c2::varchar),
SALARY number AS (value:c3::number),
DEPARTMENT_ID number AS (value:c4::number),
JOINING_DATE date AS TO_DATE(value:c5::varchar,'YYYY-MM-DD')
)
LOCATION=@my_azure_stage/
PATTERN='.*employee.*[.]csv'
FILE_FORMAT = (TYPE = CSV SKIP_HEADER = 1)
;The table can be queried like any other Snowflake table as shown below. By default VALUE variant column is available in external table.
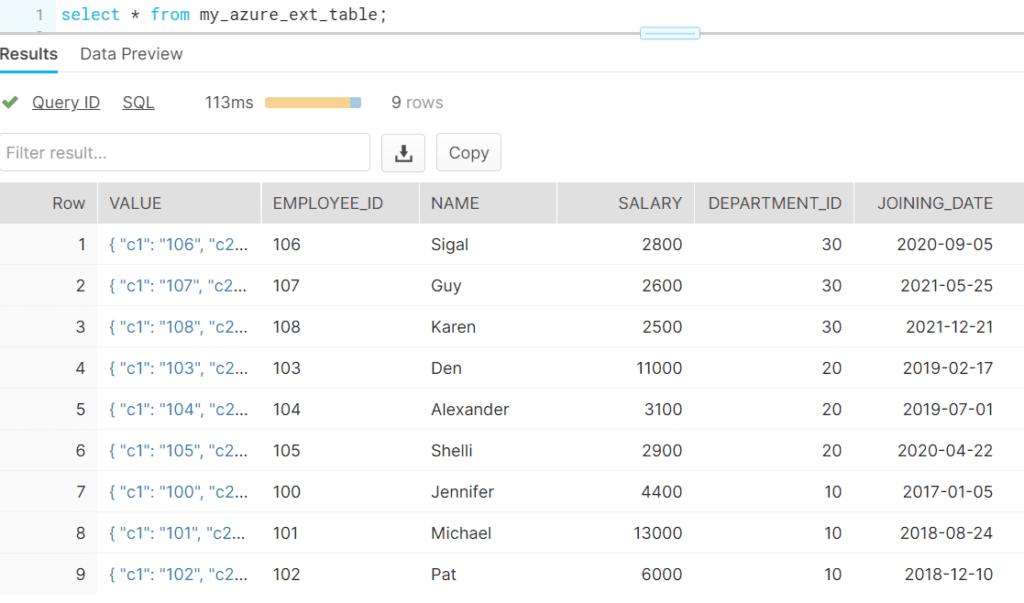
Creating Partitioned External tables in Snowflake
A Snowflake External table can be partitioned while creating using PARTITION BY clause based on logical paths that include date, time, country, or similar dimensions in the path. Partitioning divides your external table data into multiple parts using partition columns.
A partition column must evaluate as an expression that parses the path and/or filename information in the METADATA$FILENAME pseudocolumn which is included with external tables.
In the example discussed above let us create a partition on Department name. The below example shows how the required partition information can be fetched using METADATA$FILENAME pseudocolumn.
SELECT DISTINCT split_part(metadata$filename,'/',1) FROM @my_azure_stage/;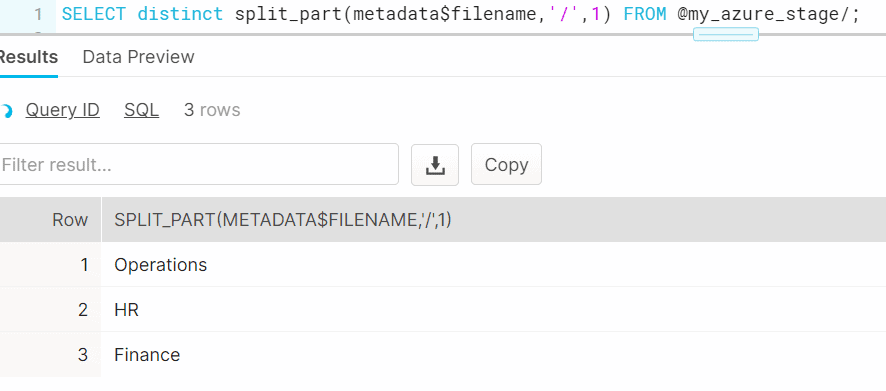
The below example shows creating a partitioned external table in Snowflake
CREATE OR REPLACE EXTERNAL TABLE my_azure_ext_table(
DEPARTMENT varchar AS split_part(metadata$filename,'/',1),
EMPLOYEE_ID varchar AS (value:c1::varchar),
NAME varchar AS (value:c2::varchar),
SALARY number AS (value:c3::number),
DEPARTMENT_ID number AS (value:c4::number),
JOINING_DATE date AS TO_DATE(value:c5::varchar,'YYYY-MM-DD')
)
PARTITION BY (DEPARTMENT)
LOCATION=@my_azure_stage/
PATTERN='.*employee.*[.]csv'
FILE_FORMAT = (TYPE = CSV SKIP_HEADER = 1)
;Partitioning your external table increases query response time while querying a small part of the data as the entire data set is not scanned.
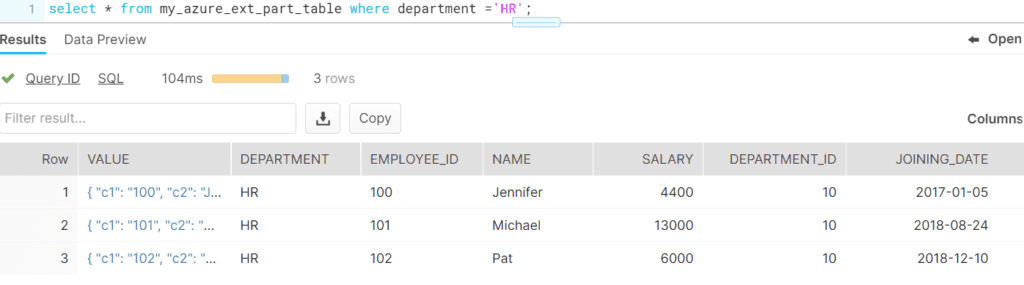
Refreshing Metadata of Snowflake External tables
Currently the external tables cannot refresh the underlying metadata of files to which they point automatically.
It should be periodically refreshed using the below alter statement manually.
ALTER EXTERNAL TABLE my_ext_table refresh;To automatically refresh the metadata for an external table, following event notification service can be used for each storage location:
- Amazon S3: Amazon SQS (Simple Queue Service)
- Microsoft Azure: Microsoft Azure Event Grid
- Google Cloud Storage: Currently not supported.
We will discuss in detail the steps to automatically refresh the metadata for an external table in a separate article.
How are Snowflake External Tables different from database tables?
- External tables are read-only and no DML operations are supported on them.
- In an external table, the data is not stored in database. The data is stored in files in an external stage like AWS S3, Azure blob storage or GCP bucket.
- External tables can be used for query and can be used in join operations with other Snowflake tables.
- Views and Materialized views can be created against external tables.
- Time Travel is not supported.
Final Thoughts
Situations like where files with file formats like Parquet in which the data cannot be read directly by opening the file in an editor, the Snowflake external tables comes very handy to read the files and verify the data inside them.
The ability to query a file in external location as a table and the provision to join them with other Snowflake tables opens up numerous advantages such as ease of accessing and joining the data between multiple cloud platforms and effortless ETL pipelines development.
Related Articles:

A definitive guide on how to download, install, configure and use Snowflake SnowSQL Command Line tool

A complete guide to types of Snowflake Stages and how to load data into and unload data from Snowflake tables using stages.

Learn how to create external stages on AWS S3, Microsoft Azure and Google Cloud platforms in Snowflake.

