
Introduction
Snowflake supports loading semi structured data like JSON in database tables. Once the data is loaded from stage into a database table, Snowflake has an excellent functionality for directly querying semi-structured data along with flattening it into a columnar structure.
In this article, let us discuss the entire process of loading and parsing JSON data in Snowflake.
Local Machine → Snowflake Internal Stage → Database table → Querying and Flattening the JSON data
For the demonstration, we will consider below JSON data containing novel’s information of three authors.
[
{
"AuthorName": "Author-1",
"Category": [{
"CategoryName": "Fiction",
"Genre": [{
"GenreName": "Action and Adventure",
"Novel": [{
"Novel": "Novel-1",
"Sales": "200"
},
{
"Novel": "Novel-2",
"Sales": "850"
}
]
},
{
"GenreName": "Romance",
"Novel": [{
"Novel": "Novel-3",
"Sales": "400"
}]
}
]
},
{
"CategoryName": "NonFiction",
"Genre": [{
"GenreName": "Autobiography",
"Novel": [{
"Novel": "Novel-4",
"Sales": "900"
}]
}]
}
]
},
{
"AuthorName": "Author-2",
"Category": [{
"CategoryName": "Fiction",
"Genre": [{
"GenreName": "Action and Adventure",
"Novel": [{
"Novel": "Novel-5",
"Sales": "340"
}]
},
{
"GenreName": "Crime",
"Novel": [{
"Novel": "Novel-6",
"Sales": "940"
},
{
"Novel": "Novel-7",
"Sales": "540"
}
]
}
]
}
]
},
{
"AuthorName": "Author-3",
"Category": [{
"CategoryName": "Fiction",
"Genre": [{
"GenreName": "Romance",
"Novel": [{
"Novel": "Novel-8",
"Sales": "820"
},
{
"Novel": "Novel-9",
"Sales": "620"
}
]
},
{
"GenreName": "Thriller",
"Novel": [{
"Novel": "Novel-10",
"Sales": "770"
}]
}
]
},
{
"CategoryName": "NonFiction",
"Genre": [{
"GenreName": "History",
"Novel": [{
"Novel": "Novel-11",
"Sales": "450"
}]
},
{
"GenreName": "Travel",
"Novel": [{
"Novel": "Novel-12",
"Sales": "150"
}]
}
]
}
]
}
]Our goal is to load the above JSON data into Snowflake and flatten it to achieve below columnar format of the data.
| Author | Category | Genre | Novel | Sales |
| Author1 | Fiction | Action and Adventure | Novel-1 | 200 |
| Author1 | Fiction | Action and Adventure | Novel-2 | 850 |
| Author1 | Fiction | Romance | Novel-3 | 400 |
| Author1 | Non-Fiction | Autobiography | Novel-4 | 900 |
| Author2 | Fiction | Action and Adventure | Novel-5 | 340 |
| Author2 | Fiction | Crime | Novel-6 | 940 |
| Author2 | Fiction | Crime | Novel-7 | 540 |
| Author3 | Fiction | Romance | Novel-8 | 820 |
| Author3 | Fiction | Romance | Novel-9 | 620 |
| Author3 | Fiction | Thriller | Novel-10 | 770 |
| Author3 | Non-Fiction | History | Novel-11 | 450 |
| Author3 | Non-Fiction | Travel | Novel-12 | 150 |
Loading JSON data from local machine into Snowflake Internal Stage
Before we load the data, we must choose the database and schema where the data is staged and later loaded into table. For the demonstration we will be using MY_DB database and MY_DB.MY_SCHEMA schema.
USE DATABASE my_db;
USE SCHEMA my_schema;Step-1: Create a Snowflake Internal named Stage
Create an Internal Named Stage in Snowflake to hold the data loaded from local machine as shown below.
CREATE OR REPLACE STAGE my_internal_stage;Step-2: Load data from local machine into Internal Stage using SnowSQL
To load data from our local machine into the Snowflake Internal stage, we have to use the Snowflake’s CLI tool which is SnowSQL.
To know more about this, read our detailed article on Snowflake SnowSQL.
1. Login to Snowflake SnowSQL
2. Using PUT command, copy the files from the local folder into snowflake internal stage created in earlier step.
put file://C:\SourceFiles\authors.json @my_internal_stage;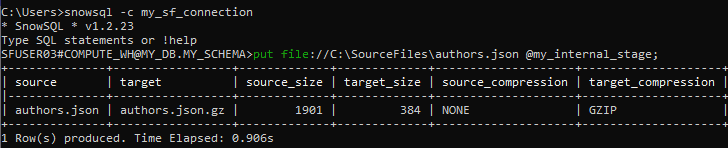
Step-3: Verify the file in Internal Stage using List command
Use List command in Snowflake worksheet to verify the file in internal stage loaded from SnowSQL as shown below.
List @my_internal_stage;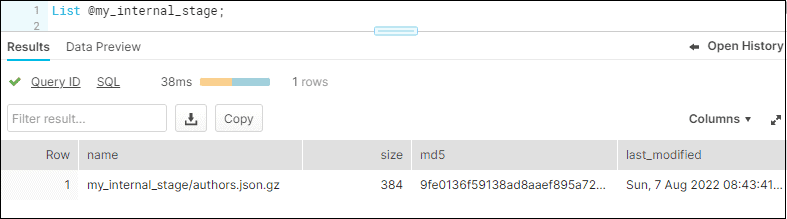
Loading JSON data from Snowflake internal Stage into database table
Step-4: Create a JSON file format in Snowflake
Create a Snowflake File format of type JSON which encapsulates information of data files which helps in processing the files from stage.
CREATE OR REPLACE FILE FORMAT my_json_format
type = json
strip_outer_array = true
;We have used an option called STRIP_OUTER_ARRAY for this load. It helps in removing the outer set of square brackets [ ] when loading the data, separating the initial array into multiple lines. Else the entire JSON data gets loaded into single record instead of multiple records.
Step-5: Create database table to load JSON data
Create a table to load JSON data from Snowflake internal stage as shown below. Snowflake stores semi-structured data using the VARIANT field type in tables.
CREATE OR REPLACE TABLE Authors (
JSON_DATA VARIANT
);Note that the data of each author in the JSON file will be loaded into a single column JSON_DATA of type VARIANT in the table named Authors.
Step-6: Load data from Internal Stage into database table using COPY command
COPY command in Snowflake helps in loading data from staged files to an existing table. Load the data from a JSON file in internal stage to Authors database table using the MY_JSON_FORMAT file format as shown below
COPY INTO Authors
FROM @my_internal_stage/authors.json
FILE_FORMAT = (format_name = MY_JSON_FORMAT);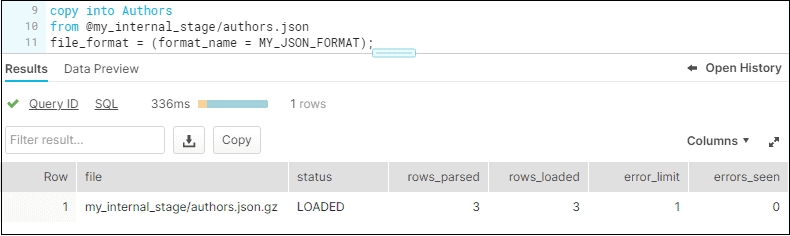
Querying JSON data from Snowflake database table
The data from the Authors table can be queried directly as shown below. By using the STRIP_OUTER_ARRAY option, we were able remove this initial array [] and treat each object in the array as a row in Snowflake. Hence each author object loaded as a separate row.
SELECT * FROM Authors;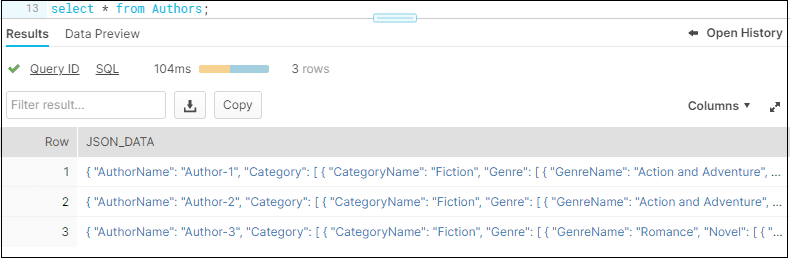
The individual elements in the column JSON_DATA can be queried using standard : notation as shown below.
SELECT
JSON_DATA:AuthorName,
JSON_DATA:Category
FROM Authors;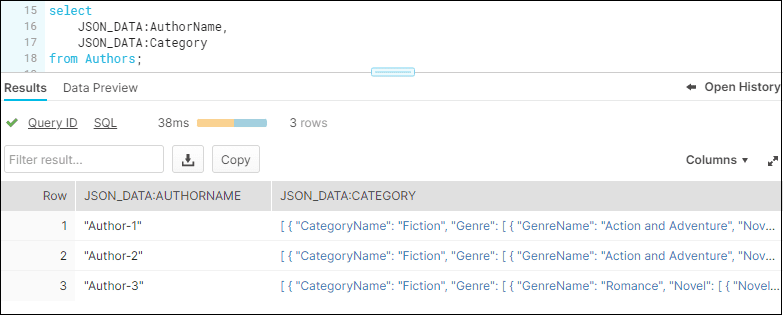
The data in the Category can be further drilled down and required elements information can be fetched as shown below.
SELECT
JSON_DATA:AuthorName,
JSON_DATA:Category[0]:CategoryName,
JSON_DATA:Category[1]:CategoryName
FROM Authors;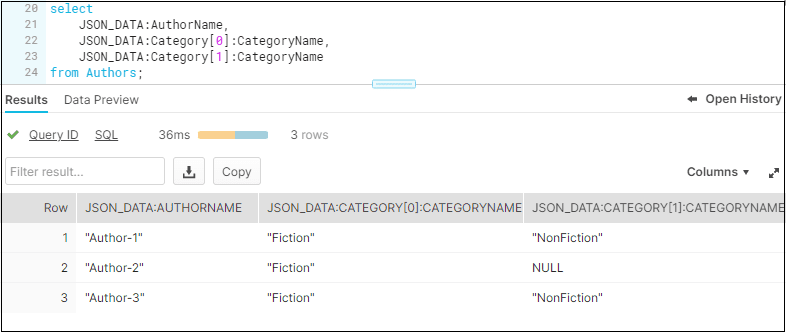
The novels of the authors are categorized into two different types in the JSON data. The details of each category can be accessed using the index [0], [1].. notation as shown above.
The outer quotes in the column data can be removed by using :: notation which lets you define the end data type of the values being retrieved. Notice how in this example, the outer quotes “ are removed.
SELECT
JSON_DATA:AuthorName::string,
JSON_DATA:Category[0]:CategoryName::string,
JSON_DATA:Category[1]:CategoryName::string
FROM Authors;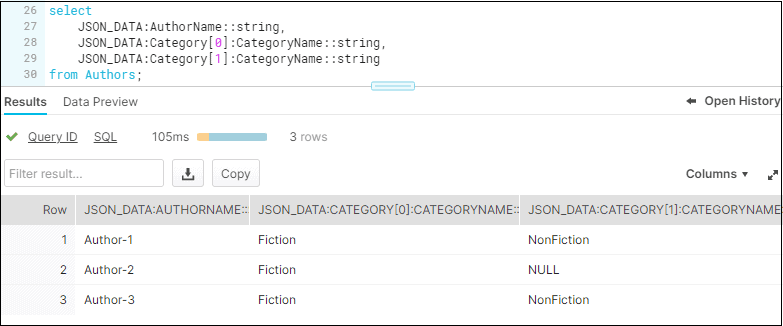
Further more details of author can be drilled down as shown below.
SELECT
JSON_DATA:AuthorName::string,
JSON_DATA:Category[0]:CategoryName::string,
JSON_DATA:Category[0]:Genre[0]:GenreName::string,
JSON_DATA:Category[0]:Genre[1]:GenreName::string,
JSON_DATA:Category[1]:CategoryName::string,
JSON_DATA:Category[1]:Genre[0]:GenreName::string,
JSON_DATA:Category[1]:Genre[1]:GenreName::string
FROM Authors;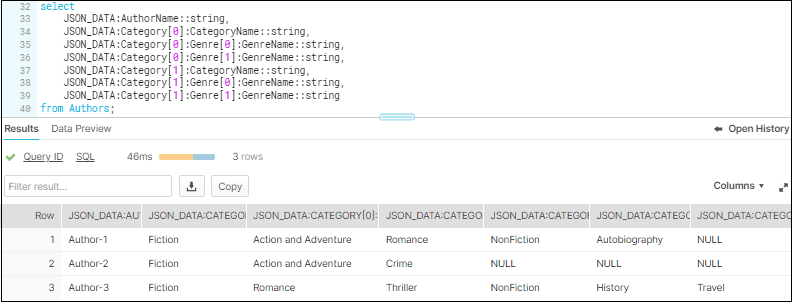
Unfortunately, this approach is not ideal. As the data increases, you need to add additional levels of category and genre in the query statement specifying the index values. Using the : and [] notation alone is not sufficient to dynamically get every object in an array.
Flattening Arrays in JSON data
Flattening is a process of unpacking the semi-structured data into a columnar format by converting arrays into different rows of data.
Using the LATERAL FLATTEN function we can explode arrays into individual JSON objects. The input for the function is the array in the JSON structure that we want to flatten (In the example shown below, the array is Category). The flattened output is stored in a VALUE column. The individual elements from unpacked array can be accessed through the VALUE column as shown below.
SELECT
JSON_DATA:AuthorName::string AS Author,
VALUE:CategoryName::string AS CategoryName
FROM Authors
,LATERAL FLATTEN (input => JSON_DATA:Category);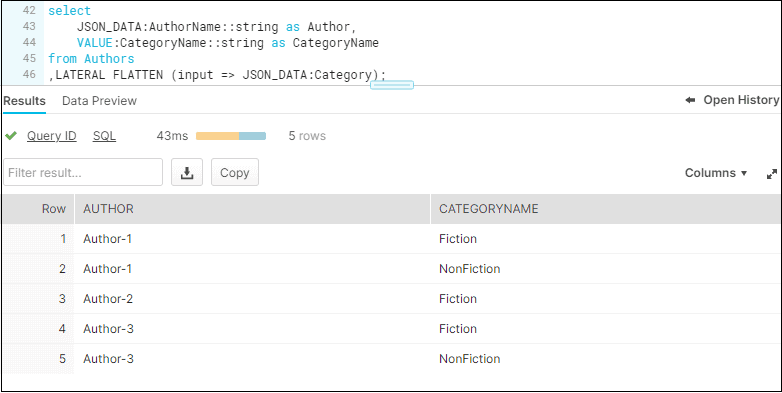
When there are multiple arrays which you need to flatten, it is mandatory to pass an alias to every input array. The VALUE column also should be used along with the alias you passed to the input array.
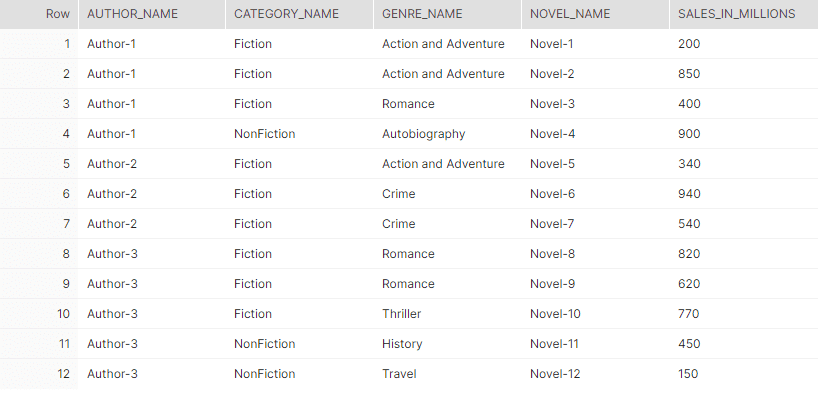
In our example, we need to flatten the Category, Genre and Novel arrays to get the desired output. Also note that the Novel array is present inside Genre array which is present inside Category array. So the flattened array output VALUE becomes input for the array present inside it.
The final query to get the desired output is as below.
SELECT
JSON_DATA:AuthorName::string AS Author_Name,
Flatten_Category.VALUE:CategoryName::string AS Category_Name,
Flatten_Genre.VALUE:GenreName::string AS Genre_Name,
Flatten_Novel.VALUE:Novel::string AS Novel_Name,
Flatten_Novel.VALUE:Sales:: number AS Sales_in_Millions
FROM Authors
,LATERAL FLATTEN (input => JSON_DATA:Category) AS Flatten_Category
,LATERAL FLATTEN (input => Flatten_Category.VALUE:Genre) AS Flatten_Genre
,LATERAL FLATTEN (input => Flatten_Genre.VALUE:Novel) AS Flatten_Novel
;
Summary
Snowflake supports loading semi structured data files from external and internal stages into database tables. Once the data is loaded into the table, it is important to understand the data structure and identify the arrays to flatten which provides the required output. The transformed data can then be loaded into another database tables with proper field names and data types easily.
This is a good example of Snowflake’s ELT features which is extremely helpful as the semi structured data can be easily transformed once loaded without the help of external ETL tools.
Subscribe to our Newsletter !!
Related Articles:

A definitive guide on how to download, install, configure and use Snowflake SnowSQL Command Line tool

A complete guide to types of Snowflake Stages and how to load data into and unload data from Snowflake tables using stages.

Learn how to create external stages on AWS S3, Microsoft Azure and Google Cloud platforms in Snowflake.

