
Introduction
There are two different ways in which the mapping tasks built in Informatica Cloud Data Integration could be exported. In one method the task could be exported as a zip file which in turn stores the metadata of the mapping task in form of JSON and in other method the task could be exported as a XML file.
There is a difference in the way metadata of the task gets stored in JSON and XML files in Informatica Cloud. This difference can be made used to build an automation which solves a unique use case.
In this article let us discuss in detail how to export the tasks in Informatica Cloud in different ways, their particular usage scenarios and the differences in the metadata stored in XML and JSON and how to join them to our advantage.
How to Export mapping tasks as a ZIP file in IICS?
In order to export the mapping tasks as a zip file in Informatica Cloud
- Login to Informatica Cloud Data Integration Service.
- Click on Explore and navigate to the desired project folder.
- Select all the mapping tasks you want to export from the folder by clicking on the box present on left side of each task.
- Right click on any task after selecting the desired tasks.
- Click on Export option from the pop-up menu.
- You will be asked to enter a name for the file you wanted to export.
- By default, the Include all dependencies for the selected assets option will be enabled which fetches all the dependent jobs and assets of the tasks you are exporting.
- Enter the name of the zip file and click Export.
- Navigate to My Import/Export Logs on the left side menu and select the Export tab.
- Find the entry with the name you provided while exporting with ‘Export Completed Successfully’ status and click on Download button present on the right side.
- A zip file will be downloaded into your local machine. This file stores the metadata of the tasks you exported in form of JSON.
Points to keep in mind regarding JSON export in Informatica Cloud
- The advantage of exporting tasks in this method is that multiple tasks can be exported at a time in a single export file which stores the metadata of all the tasks in the form of JSON.
- You can literally export the entire project folder with hundreds of mapping tasks as a single zip file.
- You can import the tasks into another org using the exported zip file. The tasks can be easily imported by selecting the Import option in Explore tab and selecting the zip file you exported. You can also select which tasks to import out of all the tasks present in the export file.
How to Export mapping tasks as a XML file in IICS?
In order to export the mapping tasks as a zip file in Informatica Cloud
- Login to Informatica Cloud Data Integration Service.
- Click on Explore and navigate to the desired project folder.
- Select all the mapping task you want to export from the folder by clicking on the box present on left side of the task.
- Right click on any task after selecting the desired mapping task.
- Click on Download XML option from the pop-up menu.
- The task will be exported in form a XML file into your local machine.
Points to keep in mind regarding XML export in Informatica Cloud
- You can export only one task at a time in form of XML. If you need to export multiple tasks you need to download each XML file individually.
- You cannot export mappings in the form of XML. Only Mapping tasks, Synchronization tasks and Powercenter tasks can be exported in form of XML.
- The downloaded XML file of a mapping task can be imported into Informatica Powercenter as a workflow.
- The XML file cannot be imported into another org of Informatica Cloud. The export file needs to be exported in form of ZIP file only to import the tasks into another org.
Difference in metadata between XML and JSON export in IICS
The XML file exported from Informatica Cloud is similar to the XML file exported from Powercenter and can be imported into Powercenter also. The metadata of task stored in form of XML is exactly how Informatica Powercenter would store the task information.
The zip file exported from Informatica Cloud stores data of each task separately in a separate zip file with in the zip file exported and the metadata of each task is stored in form of JSON in its own zip file. There would be a separate zip file for mapping task and its mapping and each has its own metadata file in stored in of form JSON in their own zip file.
There is a difference how the ‘Target‘ metadata information gets stored in both XML and JSON formats. In JSON format all the fields present in the target object are stored irrespective of whether the field is mapped or not. Whereas the XML file stores only the field information which are mapped in the target.
We can make use of this particular behaviour and build an automation which solves a unique use case by joining the XML and JSON export files of a task.
Let us understand the automation use case with an example.
Automation Use Case
For example, I have a mapping with CSV file as a source loading data into Salesforce ACCOUNT object. The CSV file contains 11 fields and are mapped to the target ACCOUNT object fields. Out of 192 total fields in ACCOUNT, 11 fields are mapped and remaining 181 fields are not mapped.
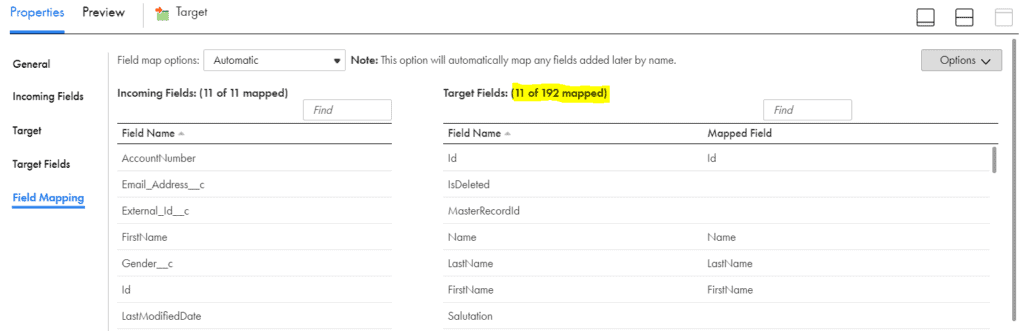
Imagine I have such multiple mappings wherein I need to find the information of fields which are mapped and not mapped in the target.
This can be actually expanded into a broader use case. When there are hundreds of such mappings and you want to identify if a particular target field is mapped or not in those particular set of mappings, this would be a handy tool.
I definitely don’t say that this is a regular use case, but I faced with such scenario once and it always good to know that this can be achieved in Informatica Cloud.
This is in fact an extension to Auto Review Tool and the Impact Analysis Tool that I have discussed in my previous Automation articles. If you have landed here first, going through them will make a lot of sense as I would be making a lot of references to what I have discussed in those articles.
How XML and JSON metadata of mapping are connected?
There is only one common element in both JSON and XML files which actually helps in joining them. The common element is Workflow Name.
The Workflow name from XML file is available under POWERMART/REPOSITORY/FOLDER/WORKFLOW/NAME

The Workflow Name is appended with ‘wf_mtt_’ which needs to be removed before actually joining with JSON Workflow Name.
The extraction of Workflow Name of JSON file is not a straightforward process. In order to fetch the Workflow Name, you need to first unzip the exported zip file. After unzipping you will find a JSON file with name “exportMetadata.v2.json”. This file will store Workflow Names of all the mappings you exported from Informatica Cloud.
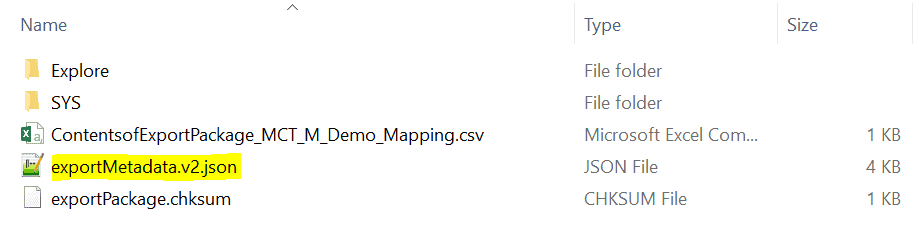
The Workflow Name is available under root/exportedObjects/repoInfo/repoHandle
You will have to build a separate mapping to read the exportMetadata.v2.json file and fetch the Workflow name information of each Mapping task into a CSV file. This file can later be used to join the XML data with JSON data.
How to fetch Fields information from JSON file?
In my previous article regarding the Auto Review Tool, I have explained in details how to fetch fields information from a mapping JSON file. The same can be extended and used to read field information from JSON file.
Since we only need fields information from target transformation only filter the unwanted fields and read only the target fields information.
Below is the final output with all the 192 JSON fields information.
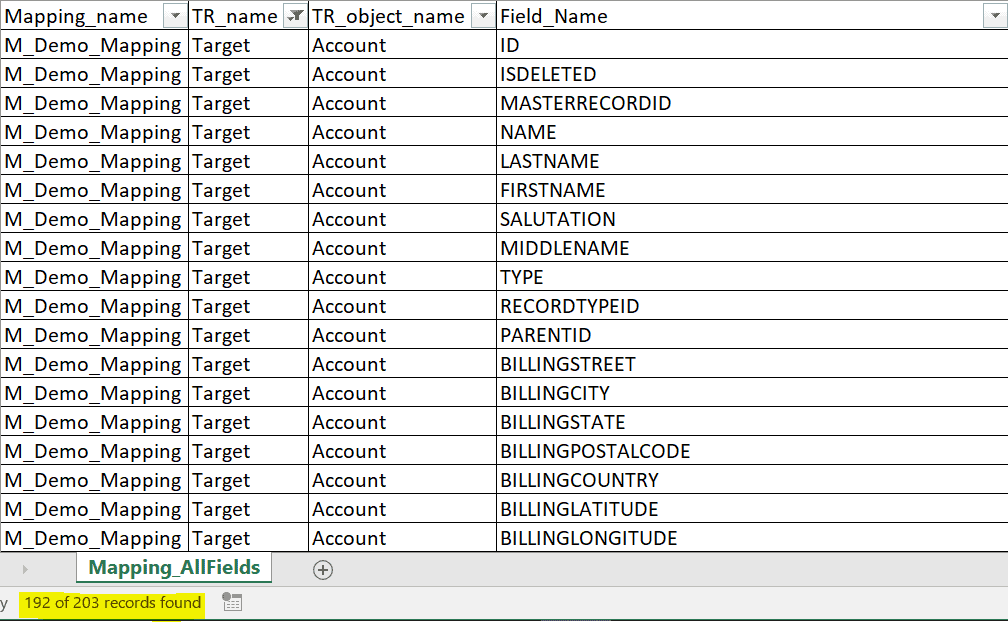
As discussed, the JSON files stores all the information of the target fields which are both mapped and unmapped but there is no information (I think it is safe to say that I could not find) that points out whether the field is mapped or not.
How to fetch Fields information from XML file?
The mapping development process is similar to how we fetch the field information from JSON file.
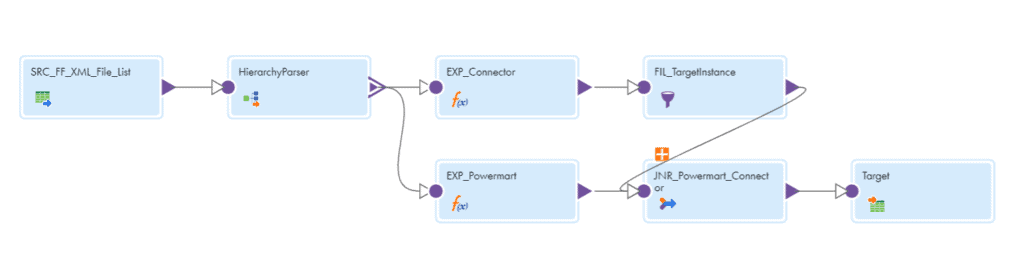
Source:
- The Source transformation reads a flat file containing the list of all the mapping XML files as a source.
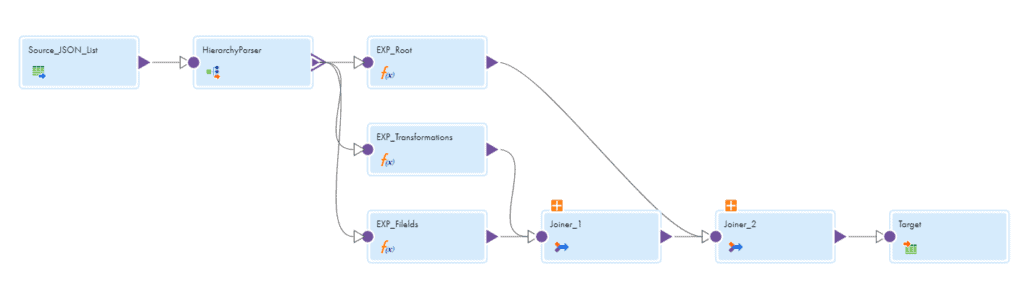
Hierarchy Parser:
- The Hierarchy Parser transformation reads the XML files one after the other and provides a relational output. A Hierarchical Schema needs to be defined initially in order to use Hierarchy Parser transformation.
- The Hierarchy Parser parses the JSON input into below relational format.
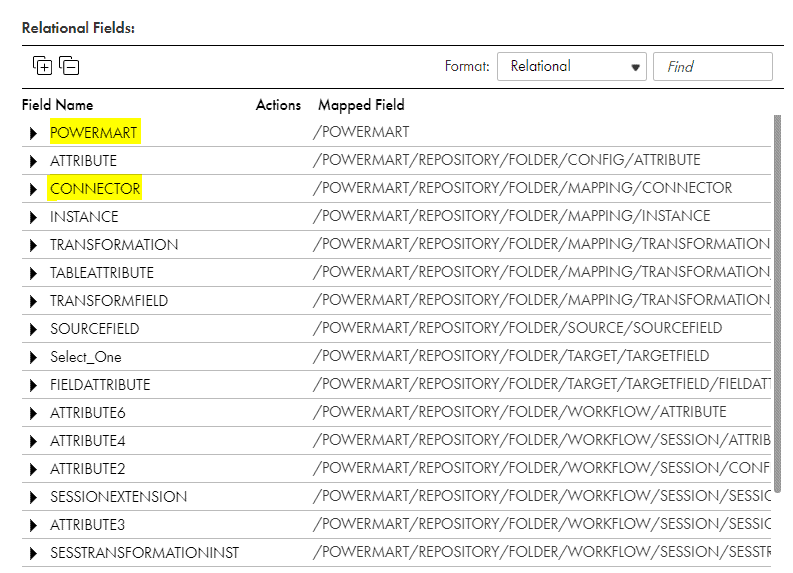
- Out of all the field segments we are going to use POWERMART and CONNECTOR to fetch the fields information from XML file.
Expression:
- Take the output from Hierarchy parser into two expressions which read the POWERMART and CONNECTOR information.
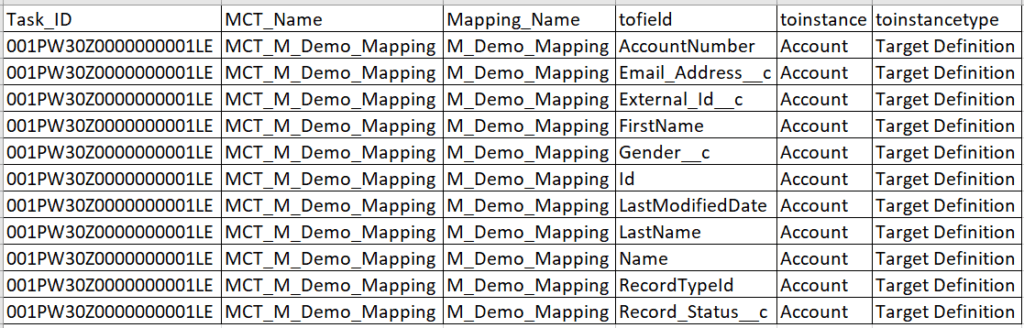
- CONNECTOR contains the XML fields information which are mapped in the target. Below are the fields present in CONNECTOR read from Hierarchy Parser.
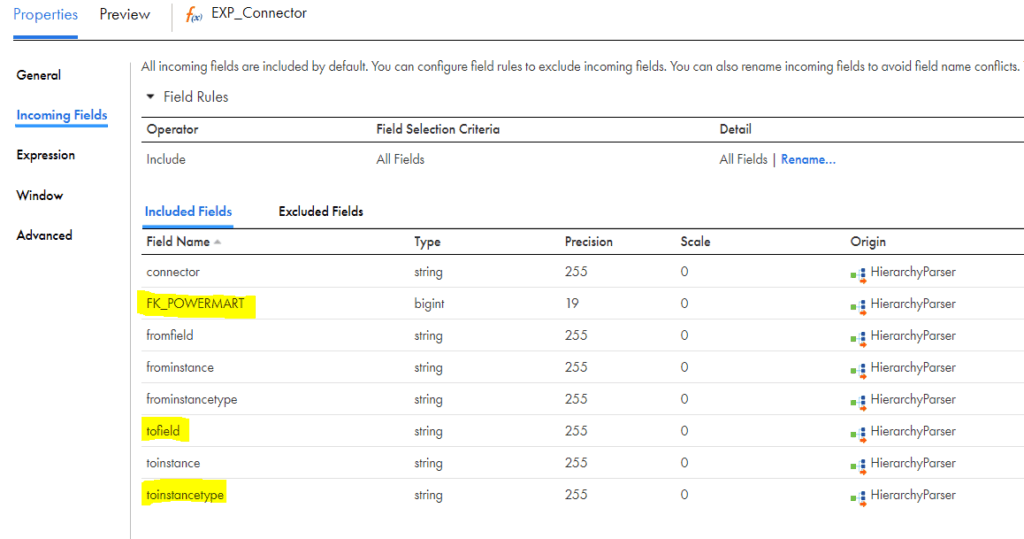
- The field ‘tofield’ contains field name information and the field ‘toinstancetype’ contains the target object name.
- POWERMART contains the Workflow Name details. Below are the fields present in CONNECTOR read from Hierarchy Parser.
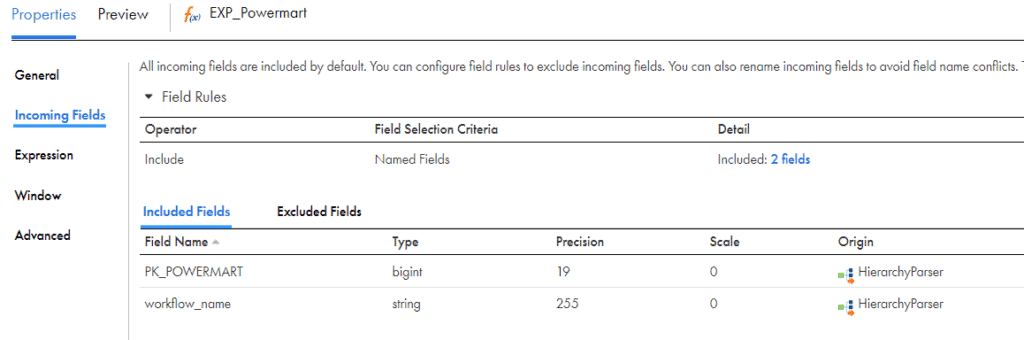
- Using the Workflow Name information fetch the Mapping Task Name details by looking up on the CSV file created by reading exportMetadata.v2.json file.

- Since the workflow_name has ‘wf_mtt_’ appended in the beginning that is removed using the variable field V_Task_ID.
- Using the V_MCT_Name we are looking up based on the workflow name and fetching the Mapping Task Name.
- In the AutoReview Tool, we have discussed how to fetch the mapping name using the Mapping task name. Similar process is used to fetch the Mapping Name using the MCT_Name of the task.
Filter:
- Since we only need fields information from target transformation, filter the target instance records coming from CONNECTOR expression using filter transformation.
toinstancetype=’Target Definition’
Joiner:
- Join the data coming from CONNECTOR and POWERMART using below condition.
FK_POWERMART = PK_POWERMART
Target:
- The target transformation writes XML fields information to a CSV file. Below is the final output with the 11 XML fields information which are mapped.
How to join the XML and JSON fields of same mapping?
Now that we have the Mapping Name, Object Name and Field Name information for both XML and JSON files, they both can be joined using a Joiner transformation with JSON fields information file as Master and XML fields information as Detail and Join Type as Detail Outer.
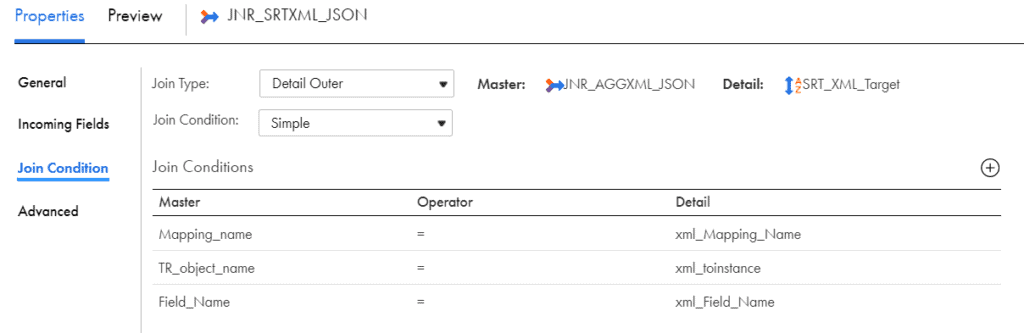
The Detail Outer join gives all the fields from JSON and the matching fields from XML. Hence out of 192 JSON fields, 11 fields will have XML fields information and the rest 181 fields will have XML field value as NULL.
The fields with XML field information can be assigned with status as ‘FIELD MAPPED’ and those with XML filed value as NULL can be assigned with ‘FIELD NOT MAPPED’ status.
Conclusion
This is going to be a One-Time setup and all you need to pass is both ZIP file and XML files of mapping tasks exported from IICS as input to the tool and it would provide the information of field map status in the target.
I understand this a very rare requirement and would be useful if you are having a change in the target structure which is used in multiple mappings. But we are only scratching the surface here and just using only a little information from both XML and JSON metadata files.
The fact that we can now join XML and JSON metadata files will open up a huge possibility to automate a wide range of requirements and we have discussed only one out of many here.



How can we automate mapping task creating by just feeding important value in it for the dynamic use. rather manually creating each mapping task can we automate this through python script.
It is possible according to this Informatica article.
Will try to research from my end and publish a detailed article soon.